原文はこちら。
The original article was written by Filip Wilén (KTH, School of Electrical Engineering and Computer Science (EECS)).
https://inside.java/2023/04/03/hotspot-throughput-thesis/
ここで紹介する研究は、Oracle、Uppsala University、KTHの共同研究プロジェクトの一環として行われたものです。
Oracle, Uppsala University, and KTH in joint JVM research projects
https://inside.java/2020/06/12/joint-research-projects/
StockholmのOracle Developmentオフィスで行われたJVMの研究の詳細は、inside.javaをご覧ください。
私Filip Wilénは、2022年秋にオラクルで修士論文を書きました。この論文は、OracleのStockholmオフィスとの共同研究です。Roberto Castañeda LozanoとOracleのチームには、このプロセスを通して経験と指導をいただき、深く感謝しています。
Roberto Castañeda Lozano
https://inside.java/u/RobertoCastanedaLozano/
私の修士論文では、OpenJDK Hotspotのconcurrent GCであるgenerational ZGCに対して、safepoint attached-barriers (SAB) と呼ばれる最適化案のスループット評価を行いました。論文の主な課題は、この最適化によって大きなスループット効果が得られるかどうかを答え、最適化の主なスループット制限を見つけることでした。この知識は、ZGCのリリース・バージョンにSABを実装すべきかどうかの決定に利用できます。論文の全文はこちらでご覧いただけます。
Throughput Analysis of Safepoint-attached Barriers in a Low-latency Garbage Collector: Analysis of a Compiler Optimization in the HotSpot JVM
https://kth.diva-portal.org/smash/record.jsf?pid=diva2%3A1737851&dswid=-341
Background
concurrent memory management(並行メモリ管理)の背後にある考え方は、アプリケーション・スレッドとGCスレッドを同時に実行するというものです。しかし、この場合、アプリケーションとGCが同時にJavaヒープにアクセスするため、ポインタが誤ったメモリ・フィールドを参照する可能性があります。この問題に対処するため、Generational ZGCはポインタ参照をチェックし、必要であれば正しいアドレスに復元するバリアを、Store/Load操作ごとに使用します。残念ながら、これらのバリアはオーバーヘッドをもたらしますが、理論的には、バリアが必要なのはヒープが再配置された場合だけです。そのため、safepoint-attached barriers (SAB) と呼ばれるJITコンパイラ最適化が提案されています。これはヒープの安定性が保証されるプログラムのセクションでバリアの数を減らすことを目的としています。単純化した例として、SABは、以前に別のバリアがバリアが取り除かれたメモリフィールドをチェックしたことをアルゴリズムで保証できる場合、ヒープの完全性を保証し、バリアを取り除きます。その結果、不要なバリアが除去され、スループットが向上します。
Expected Throughput Benefit of Safepoint-attached Barriers
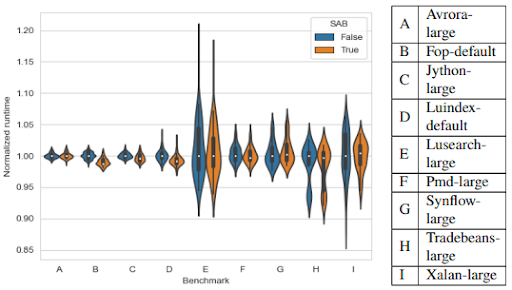
この最適化は、SPECjvm2008 [1] および DaCapo2009 version 9.12-bach-MR1 [2] ベンチマ ーク・スイートで評価しました。Figure 1は、DaCapo ベンチマーク・スイートに含まれるベンチマークの正規化実行時間を示しています。SPECjvm および DaCapo のうち、中央値で統計的に有意なスループットの改善を示したベンチマークは、 21 ベンチマークのうち 4 つのみでした。fop-defaultベンチマークでは、実行時間が約 1 %短縮され、最も改善されました。残りの17個のベンチマークでは、有意な減少は見られませんでした。これはつまり、SABが明らかなスループットに対する制約を引き起こさず、特定のベンチマークにおいてのみ統計的に有意なスループット向上をもたらしたということです。
Counting Barriers
SAB最適化のスループット上の利点は、バリア解消数に依存します。バリアは静的にも動的にもカウントできます。
| 静的なカウント(Static counting) | コード内でバリアが発生するたびにカウントする |
| 動的なカウント(dynamic counting | 実行時にバリアに到達するたびにカウントする |
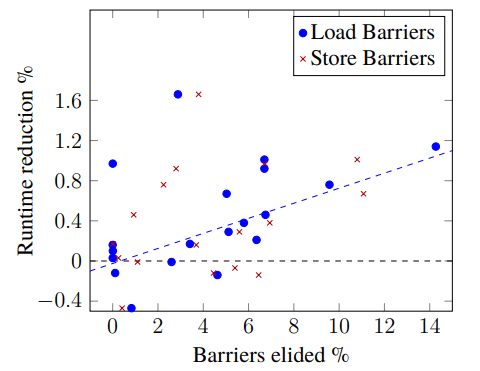
バリアをカウントするには、JVMにインスツルメンテーション・ツールを実装する必要があります。このツールを使用すると、ほとんどのベンチマークで、一般的に10~20%の静的バリアが除去できると判断できるのですが、除去される動的バリアの数は大幅に少ないことが多いのです。このことから、repeated code(繰り返されるコード)からのバリア除去に既存の限界がありそうなことがわかります。Figure 2は、DaCapoおよび SPECjvmベンチマークスイートから除去された動的バリアの中央値の割合と、実行時間の短縮との相関関係を示しています。この散布図から、実行時間の短縮と除去された動的バリアには相関関係がありそうです。
Limitations of Safepoint-attached Barriers in ZGC
DaCapoベンチマーク・スイート内の動的バリア除去率をさらに評価することで、2つの主要なSABの限界を発見できました。repeated codeセグメントにおけるバリア除去の限界は、インライン化とJITコンパイラによる静的解析に起因します。
Inlining Limitation
インライン化とは、メソッド呼び出しが呼び出し本体で置き換えられることです。コンパイル時に追跡対象のすべてのバリアは同じコンパイル・ユニット内に存在します。つまり、あるメソッド(ルート・メソッド)が選択され、さらに多くのメソッド呼び出しをこのメソッドにインライン化します。これらは、現在のコンパイル単位で追跡できるすべてのバリアです。JITコンパイラはインライン化できるコード量に内部で制限を持っているため、この結果、どのバリアを何個削除できるかについて制限があります。SABでは、この制限により、全体的に除去されるバリアが少なくなりますが、特に繰り返されるコード・セグメントでは少なくなります。
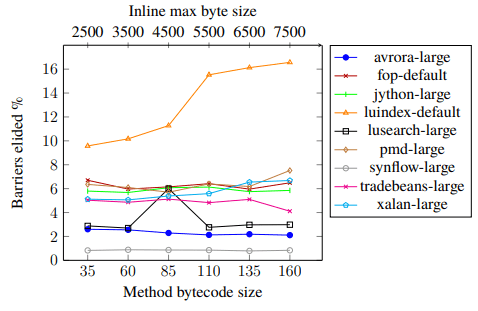
これらの制限を念頭に置くと、バリア除去を改善する簡単な解決策は、コンパイラが設定するインライン化制限の増加の可能性があります。Figure 3は、DaCapoベンチマーク・スイートでこれをテストしたもので、各データ・ポイントは、異なるインライン化制限を設定した同じベンチマークです。制限値は、Method bytecode size(インライン化されるメソッドの最大バイトコードサイズ)とInline max byte size(インライン化されるメソッドの最大バイトサイズ)で増加します。しかしFigure 3 に見られるように、ほとんどのベンチマークでは動的にエリ イドされるバリア数が大幅に増加しないため、これは明白な解決策ではなさそうです。しかしそれとは反対に、luindex-defaultベンチマークでは、インライン化判定を強化することにメリットがあることを示しています。
Static Analysis Limitation
もう1つの制約は、JITコンパイラがバリア除去のために行う静的解析です。この限界を以下のコードで説明します。コンパイラは複数回実行されても1つのバリアしか見ません。この結果、かなりの数のバリアが不必要に実行されることになります。
/*
* Listing 1: The Load barrier on line 4 cannot be removed
* even when the barrier is executed multiple times.
*/
//Limitation
while(i < 100) {
//Load barrier cannot be removed
obj load = obj.l;
i++;
}
これは、以下のコードのloop peelingの助けを借りて解決できます。メインループの外側にiteration(反復)を1つ移動させることで、ループ内のバリアが回避され、その結果、複数の動的バリアを削除できるようになります。
/*
* Listing 2: The solution to the problem in Listing 1 is to use loop peeling,
* this results in one iteration of the loop being executed before the main body.
*/
// Solution with loop peeling
obj load = obj.l;
i++;
while(i < 100) {
//Load barrier removed!
obj load = obj.l;
i++;
}
Conclusion
ほとんどのベンチマークで、SABによるスループットの増加は起こりませんでしたが、統計的に有意な増加があったとしても、その増加は1%未満でした。しかし、本論文では、loop peelingやインライン化判断の強化という形で、アルゴリズムにスループット改善の可能性があることを示しています。こうした新たなインサイトが、ZGCのリリース版でセーフポイント付きバリアを実装すべきかどうかの判断に役立つことを願っています。
References
[1] Specjvm® 2008,” Standard Performance Evaluation Corporation (SPEC), Aug 2017. [Online]. Available: https://www.spec.org/jvm2008/
[2] M. Blackburn et al., “The DaCapo benchmarks: Java benchmarking development and analysis,” in OOPSLA ’06: Proceedings of the 21st annual ACM SIGPLAN conference on Object-Oriented Programing, Systems, Languages, and Applications. New York, NY, USA: ACM Press, Oct. 2006. doi: https://doi.acm.org/10.1145/1167473.1167488 pp. 169–190.
