原文はこちら。
The original article was written by Thomas Schatzl (OpenJDK developer, Oracle).
https://tschatzl.github.io/2023/09/28/concurrent-undo.html
最近、ログに表示されるConcurrent Undo Cycleメッセージの意味について質問を受けました。このエントリでは、この最適化について、またアプリケーションにとってどのような意味があるのかについて説明したいと思います。
Introduction
G1 GCは、アプリケーションに対して同時並行でヒープ全体の有効性分析(マーキング)を行います。このプロセスは、old generationのJavaヒープ占有率が開始ヒープ占有率(Initiating Heap Occupancy Percent、IHOP)に達したときに開始します。IHOP値は、old generationへの同時マーキングとアロケーション・レートの典型的な期間に基づいて動的に計算されます。
GCがold generationのヒープ占有率がこのIHOP値に達したことに気付くと、次回のGCはConcurrent Start GCポーズとなり、続いてコンカレント・マーキングが行われます。完了後、G1はmixedフェーズを開始し、old generationのヒープ領域を収集します。
Problem
A concurrent marking cycle can take a while and takes CPU resources. For example, below log snippet shows that G1 required around 4,2 seconds to finish the concurrent marking cycle. This process includes traversing the old generation object graph and some setup for the following old generation evacuation (described in detail in this post).
コンカレント・マーキング・サイクルは時間がかかり、CPUリソースを消費します。たとえば、以下のログのスニペットでは、G1がコンカレント・マーキング・サイクルを終了するのに約4.2秒を要したことがわかります。このプロセスには、old generationのオブジェクトグラフのトラバースと、続くold generationの退避のためのセットアップが含まれます(詳細は以下のエントリで説明しています)。
Concurrent Marking in G1
https://tschatzl.github.io/2022/08/04/concurrent-marking.html
https://logico-jp.io/2022/09/17/concurrent-marking-in-g1/
[15,431s][info ][gc ] GC(12) Pause Young (Concurrent Start) (G1 Evacuation Pause) 11263M->10895M(20480M) 153,495ms
[15,431s][info ][gc ] GC(13) Concurrent Mark Cycle
[15,431s][info ][gc,marking] GC(13) Concurrent Scan Root Regions
[15,431s][debug ][gc,ergo ] GC(13) Running G1 Root Region Scan using 6 workers for 41 work units.
[15,507s][info ][gc,marking] GC(13) Concurrent Scan Root Regions 75,589ms
[15,507s][info ][gc,marking] GC(13) Concurrent Mark
[15,507s][info ][gc,marking] GC(13) Concurrent Mark From Roots
[18,731s][info ][gc,marking] GC(13) Concurrent Mark From Roots 3224,174ms
[18,731s][info ][gc,marking] GC(13) Concurrent Preclean
[18,731s][info ][gc,marking] GC(13) Concurrent Preclean 0,038ms
[18,734s][info ][gc ] GC(13) Pause Remark 11287M->11287M(20480M) 2,292ms
[18,734s][info ][gc,marking] GC(13) Concurrent Mark 3226,866ms
[18,734s][info ][gc,marking] GC(13) Concurrent Rebuild Remembered Sets and Scrub Regions
[19,687s][info ][gc,marking] GC(13) Concurrent Rebuild Remembered Sets and Scrub Regions 953,419ms
[19,688s][info ][gc ] GC(13) Pause Cleanup 11447M->11447M(20480M) 0,523ms
[19,688s][info ][gc,marking] GC(13) Concurrent Clear Claimed Marks
[19,688s][info ][gc,marking] GC(13) Concurrent Clear Claimed Marks 0,044ms
[19,688s][info ][gc,marking] GC(13) Concurrent Cleanup for Next Mark
[19,695s][info ][gc,marking] GC(13) Concurrent Cleanup for Next Mark 6,145ms
[19,695s][info ][gc ] GC(13) Concurrent Mark Cycle 4263,187ms
では、Concurrent Startポーズの後、コンカレント・マーク・サイクルを開始する条件が当てはまらなくなった場合、つまりold generationのヒープ占有率が開始しきい値を下回った場合はどうでしょうか?メモリ占有率がその必要がないことを示しているため、G1は同時マークサイクル全体を開始しません。
問題は、ポーズがConcurrent Start GCポーズにおいていくつかのグローバルな変更を行ったことです。これがConcurrent Undo Cycleの目的です。
Background
Concurrent Start GCポーズは、通常のyoung generationのGCポーズと同じです。通常のyoung generationのGCポーズでは、G1は収集するリージョン(young generation全体と収集セット候補の一部)を選択し、ルートロケーションからこれらのリージョンへの参照をスキャンします。参照されたオブジェクトとそのフォロワーは退避されます。同時に、G1はhumongous objectsの限定的で保守的な生存分析を実行し、死んだhumongous objectを即時回収しようとします。クリーンアップの後、アプリケーションは続行されます。
Concurrent Start ポーズと通常のyoung generationのGCポーズとの違いはわずかです。
- VMルート・ロケーションをスキャンしている間、G1はマーク・ビットマップ上の古い世代にロケーションをマークする。例えば、G1はオブジェクトを指すスレッドスタック上の変数からの参照をold generationにマークする。
- G1はルートリージョンを決定する。これらは、潜在的に(マークスルーされない)old generationへの参照を含むメモリ領域(通常はリージョン全体)である。
- ルートリージョンは上記のルートロケーションと似ているが、時間を節約するため、その参照はGCポーズ中にビットマップにマークされない。マーキングサイクルに含まれる続くConcurrent Root Region Scanは、ルート・リージョンの生存オブジェクトをスキャンして、old generationへのこのような参照を探し、その参照先をビットマップにマークする。このようなリージョンの例はSurvivorリージョンであるが、次のGCで収集される(潜在的にマーキング中に)コレクションセット候補リージョンでもある。後者の例は、退避が失敗したリージョンである。
上記のコレクションセット候補領域の退避と即時回収は、場合によっては、GCポーズ後にold generationの占有率が著しく小さくなることを意味します。
The Change
JDK-8240556では、同時マーキングサイクルのショートカットが実装されています。
[JDK-8240556] Abort concurrent mark after effective eager reclamation of humongous objects
https://bugs.openjdk.org/browse/JDK-8240556
ラージ・オブジェクトのイージー・リクレアムのためにConcurrent Startポーズ中にold generationのヒープ占有率がIHOP値を下回った場合、以下の状態図に示すようにマーキング・サイクル全体を実行する代わりに、G1は右の青い矢印で示すショートカットを実行します。
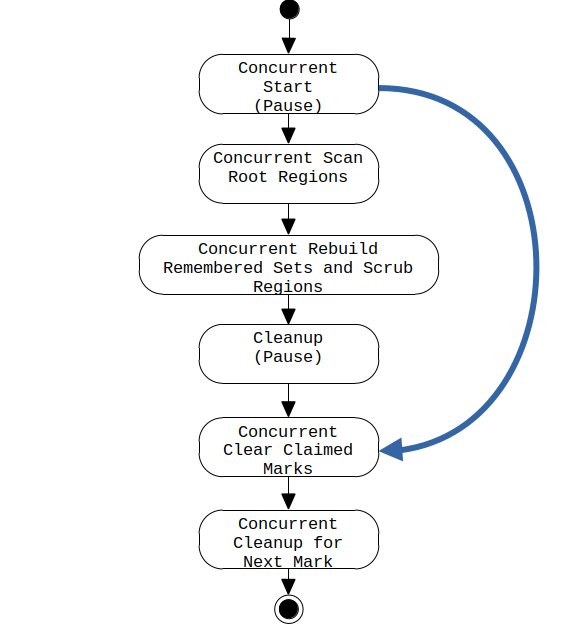
上記ログメッセージは、スキップされた状態が結果としてCPU利用率(および時間)の大幅な節約につながることを示しています。残りの状態は以下のようにConcurrent Undo Cycleを構成します。
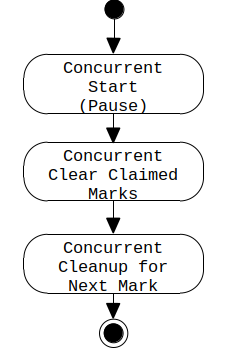
これらは対応するログ出力に反映されます。次の例は、このようなConcurrent Undo Cycleのスニペットです。
[6278.870s][info][gc ] GC(54) Concurrent Undo Cycle
[6278.870s][info][gc,marking] GC(54) Concurrent Clear Claimed Marks
[6278.886s][info][gc,marking] GC(54) Concurrent Clear Claimed Marks 0.016ms
[6278.886s][info][gc,marking] GC(54) Concurrent Cleanup for Next Mark
[6278.948s][info][gc,marking] GC(54) Concurrent Cleanup for Next Mark 77.814ms
[6278.948s][info][gc ] GC(54) Concurrent Undo Cycle 78.038ms
G1は、Concurrent Clear Claimed MarksおよびConcurrent Cleanup for Next Markフェーズのみを実行する必要があります。前者は、使用中のクラスローダーに関する内部情報をリセットし、後者は、VM内部データ構造からルート参照をマークするために使用されたマークビットマップをリセットします。それ以外はすべてスキップされます。
Concurrent Cleanup for Next Markフェーズにはまだかなりの時間がかかりますが、通常のコンカレント・マーキング・サイクルと比べると、はるかに早く終了することに注意してください。JDK-8316355に、より高速な代替案がいくつか記載されていますので、もしお気に召しましたらご連絡ください。
[JDK-8316335] G1: Improve concurrent undo cycle to be more efficient
https://bugs.openjdk.org/browse/JDK-8316355
Summary
G1においてConcurrent Undo Cycleは、コンカレントマーキングサイクルの最もCPUを消費する部分を避けるための最適化の結果であり、心配する必要はありません。もし発生しても、G1は単純にコンカレント・マーキング全体を行う必要がないことを発見しただけです。Concurrent Undo CycleはJDK 16で導入されたので、最近のバージョンのJDKを使用している場合は、すでにどちらかに遭遇しているかもしれません。
