原文はこちら。
The original article was written by Roberto Castañeda Lozano (Senior Member Of Technical Staff at Oracle).
https://robcasloz.github.io/blog/2024/02/14/when-should-a-compiler-expand-garbage-collection-barriers.html
筆者を含め、ほとんどのコンパイラ・エンジニアは、コンパイル中のプログラムに関する情報をできる限りコンパイラに公開するのが良いと信じています。その見返りとして、コンパイラがより正確な解析とより強力な最適化を実行してくれることを期待しているからです。すごいことでしょう?しかし、十分に複雑なソフトウェア製品であればあるほど、トレードオフを考慮しなければなりません。たとえば、プログラム情報を追加すると、コンパイル時間が長くなったり、コンパイラの保守性が悪くなったりするかもしれません。この投稿では、実稼働中のコンパイラ(JDKの最適化JITコンパイラであるC2)において、コンパイラに与えるプログラム情報の量を減らすことが正しいトレードオフであることがわかったケースについて説明します。
Proceedings of the Java™ Virtual Machine Research and Technology Symposium (JVM ’01)
https://www.usenix.org/legacy/events/jvm01/full_papers/paleczny/paleczny.pdf
OpenJDK
https://openjdk.org
Expanding barriers early
今回のケースは、C2におけるガベージ・コレクション(GC)バリアの内部表現に関するものです。
GC FAQ — algorithms
https://www.iecc.com/gclist/GC-algorithms.html
これは、アプリケーションのメモリ・アクセスの周囲に挿入される追加命令で、メモリ書き込みの前後にアクセスされたメモリ位置にどのような値が保持されているかなど、アクセスの詳細をガベージ・コレクタに通知します。コンパイラがGCバリアを処理する方法は複数あります。1つの方法(コンパイラ技術者に言わせれば「正しい方法」)は、コンパイラの中間表現(IR: intermediate representation)において、バリア操作を他のプログラム操作と同じように、明示的かつ一律に扱うことです。
Thinking About Intermediate Representations
https://cr.openjdk.org/~jrose/draft/code-media.html
そうすることで、コンパイラが通常の解析と変換のメカニズムを適用して、GC バリアを高度に最適化されたアセンブリコードに変換できる、というのがその論拠です。コンパイルチェーンの最初の段階でバリアがIR操作に変換されるため、私たちはこのアプローチをearly barrier expansionと呼んでいます。
The cost of early barrier expansion for G1
early barrier expansionは、G1と呼ばれるJVMのデフォルトGCが必要とするバリアに対処するための、C2における現在の選択肢です。
Garbage-first garbage collection
https://dl.acm.org/doi/10.1145/1029873.1029879
GCの中には、メモリの読み取りと書き込みの両方にバリアが必要なものがあります。GCの中には、メモリ書き込み・読み取り両方でバリアが必要なものがありますが、G1では、書き込みのみにバリアが必要なのですが、どんなバリアでもよいわけではありません。G1の書き込みバリアは100以上のIR演算で表され、約50個のx64の命令になります。メモリ書き込みはかなり一般的な演算なので、これはIRを肥大化させるだけです。C2の階乗法のIRを思い出してください。
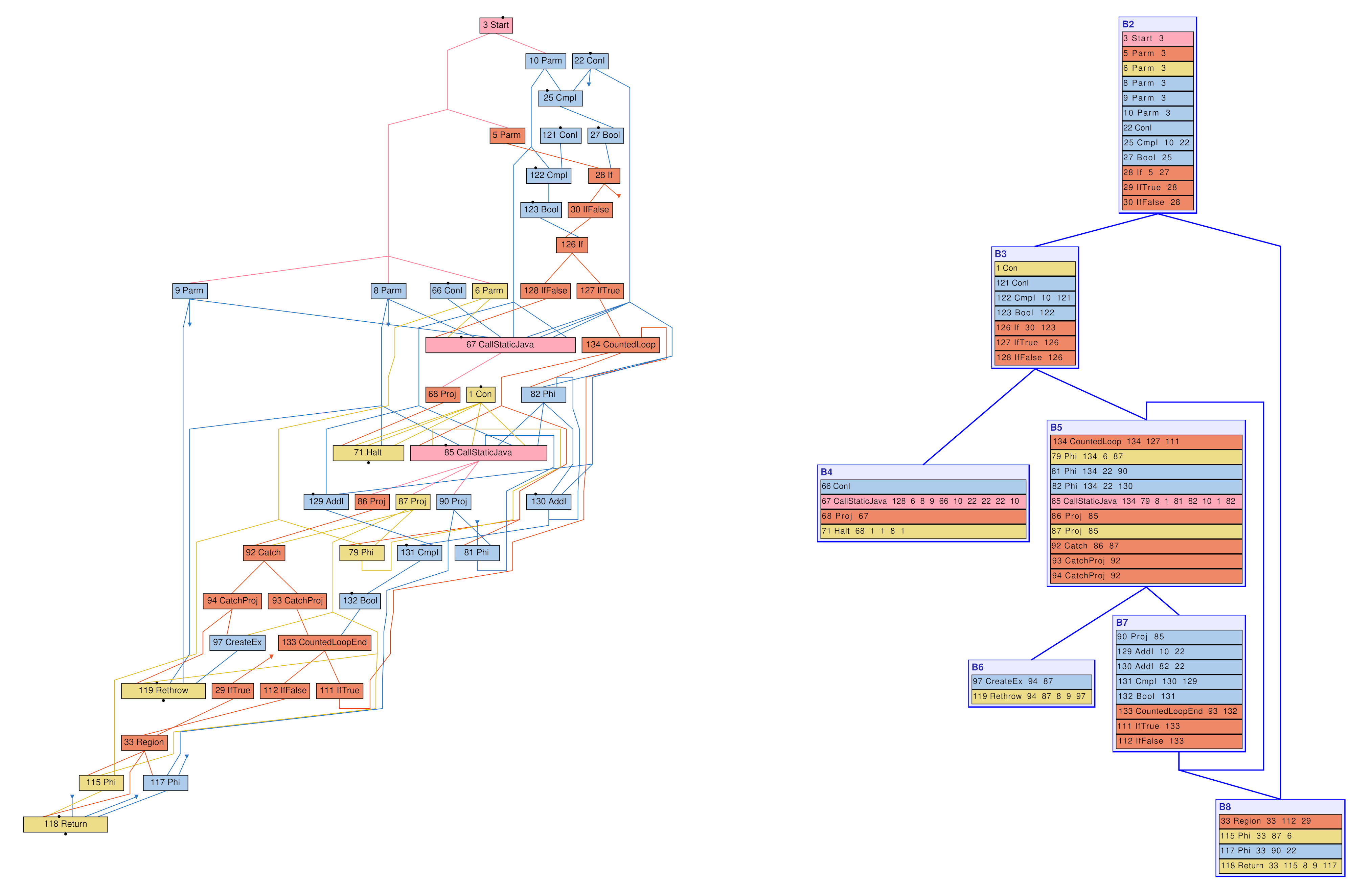
これは、オブジェクトbarを別のオブジェクトfooのフィールドfに格納する明らかに単純なメソッドなのですが、G1書き込みバリアが必要です:
void write(Foo foo, Bar bar) {
foo.f = bar;
}
以下は、対応するIRをコントロール・フロー・グラフで表したものです。
A friendlier visualization of Java’s JIT compiler based on control flow
https://robcasloz.github.io/blog/2022/05/24/a-friendlier-visualization-of-javas-jit-compiler-based-on-control-flow.html
https://logico-jp.io/2022/05/31/a-friendlier-visualization-of-javas-jit-compiler-based-on-control-flow/
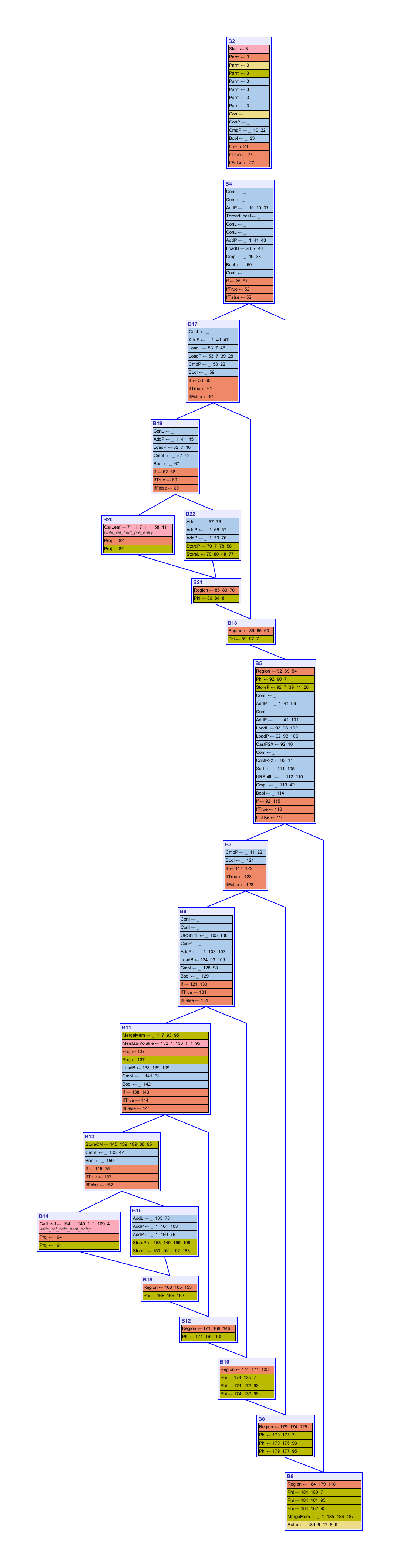
IRが大きいと、必然的にコンパイルのオーバーヘッドが大きくなります。異なるプラットフォーム(Linux/x64、macOS/aarch64)でDaCapo 9.12-bachベンチマーク・スイートを実行した予備実験では、G1バリアのIR演算はC2の総実行時間の約20%を占めています。
DaCapo Benchmarks
https://www.dacapobench.org/
The opposite approach: late barrier expansion
何ができるのでしょうか。コンパイラでGCバリアを扱う根本的に異なる方法は、コンパイル時間全体を通してコンパイラからGCバリアを単純に隠し、コード実行時にメモリアクセス命令の周りに対応する命令を「貼り付ける」だけです。この一見素朴なアプローチ(私たちはlate barrier expansionと呼んでいます)には、否定できない利点があります。非常に単純であるため、非常に安価に実装することができ、私たちの予備実験ではC2の顕著な高速化を実現しました。そして、おそらくもっと重要なことは、この機能により、GCのメンテナーは彼らが契約した覚えのない仕事から解放される点です。つまり、貴重なバリアのチューニングと最適化のために、25年前のコンパイラの複雑さや癖に対処する仕事から解放してくれるのです。
History – HotSpot (virtual machine)
https://en.wikipedia.org/wiki/HotSpot_(virtual_machine)#History
Wait, what about performance?
この時点で、この場のコンパイラ・エンジニアは、バリア展開(barrier expansion)が遅れると、確実に質の悪いコードが生成されると指摘するしかありません。なぜなら、バリア展開はアプリケーションの残りの部分と一緒に解析・最適化されるのではなく、最終的なアセンブリコードに「貼り付け」られるだけだからです。机上ではその通りですが、C2のG1バリア展開を早期から後期に移行しても、大幅な性能低下は確認されていません。G1のバリア内で最適化できる余地はそれほど多くないようで、残っている非効率性による潜在的な悪影響があるとしても、最新のプロセッサの慈悲深さによってカバーされています。
But, what if our compiler targets fifteen different platforms?
コンパイラ・エンジニアは、late barrier expansionモデルは保守性が低い、なぜならコンパイラがターゲットとするプラットフォームごとに手書きの実装が必要だからだ、と辛抱強く主張するかもしれません。これは一般的なケースでは間違いなく問題ですが、幸運なことに、JDKにはすでにバイトコード解釈のためのプラットフォーム依存のG1バリア実装が含まれており、ちょっとした手を入れるとC2用に再利用できます。
g1BarrierSetAssembler_x86.cpp
https://github.com/openjdk/jdk/blob/232d13688596e9a3c1145ee456dd5a6f7cd1223d/src/hotspot/cpu/x86/gc/g1/g1BarrierSetAssembler_x86.cpp#L163-L341
この時点で、G1ではlate barrier expansionが賢明な選択であることに、この場の全員が同意してくれることを願っています。時には、コンパイル中のプログラムの細部まで最適化したいという衝動を飲み込んで、コンパイラ設計に関わる他の多くの次元(コンパイル時間、モジュール性、保守性など)とのバランスを取る必要があります。これは、私が学界から産業界への転身で学んだ(と思いたい)教訓のひとつです。
ところで、 JDK Enhancement Proposal (JEP) の詳細についてご興味のある方は、JDKの機能強化提案の説明をご覧ください。
[JDK-8322295] Late G1 Barrier Expansion
https://bugs.openjdk.org/browse/JDK-8322295
https://openjdk.org/jeps/8322295
謝辞:この記事の草稿を校正してくれたDaniel Lundénに感謝します。
