原文はこちら。
This article was written by Milan Cugurovic (Senior Researcher at Oracle Labs.).
https://medium.com/graalvm/machine-learning-driven-static-profiling-for-native-image-d7fc13bb04e2
機械学習 (Machine Learning / ML) により、プログラムの特性に基づいて、その実行を正確に予測できるモデルのトレーニングが可能になりました。本記事では、機械学習を使って静的プロファイラ GraalSP(Native Image におけるプロファイルを予測する静的プロファイラ)を開発し、それを Oracle GraalVM Native Imageに統合し、実行時パフォーマンスを7.5%向上させることに成功した方法について説明します。
Machine Learning
https://en.wikipedia.org/wiki/Machine_learning
Native Image
https://www.graalvm.org/latest/reference-manual/native-image/
最初は静的プロファイラにについて説明し、以前の記事で取り上げた動的プロファイラと比較します。その記事ではプログラムのプロファイルと最適化をガイドする仕組みを説明していました。ソートの例を使い、GraalSPのデザインと開発について掘り下げます。最後に、機械学習をNative Imageに統合した結果を提示し、機械学習モデルの運用環境への展開についても説明します。
Profile Guided Optimizations for Native Image
https://medium.com/graalvm/profile-guided-optimization-for-native-image-f015f853f9a8
https://logico-jp.dev/2024/03/14/profile-guided-optimizations-for-native-image/
Dynamic and Static Profilers
AOTコンパイルでは、動的プロファイラは、インストルメント付きのイメージをビルドし、プロファイルを収集し、その後最適化されたイメージをビルドすることで動作します。 動的プロファイラは高品質のプロファイルを収集しますが、いくつかの欠点もあります。 まず、2回のビルドとプロファイル収集の実行が必要となるため、最適化プロセスが複雑になります。 このプロセスは通常、時間とメモリを消費するため、プログラマーや最適化に使用されるマシンに余分な負担がかかります。 また、プロファイル収集に適切な作業負荷を見つけるのは難しい場合があります。
幸い、run-build-run(実行-ビルド-実行)のコンパイルサイクルを繰り返したり、プロファイル収集に適した入力値を探す必要のない、より安価な代替手段があります。それは「静的プロファイリング」または「静的プロファイル予測」と呼ばれています。静的プロファイラとは、プログラム実行中にプロファイルを収集しないプロファイラであり、代わりにプログラムのプロファイルを予測します。最先端の静的プロファイラは、機械学習モデルを活用し、プログラムの特徴を示す一連の静的特徴に基づいてプロファイルを予測します。
図1は、機械学習モデルを活用する静的プロファイラによるプロファイルガイド付き最適化(Profile-Guided Optimization / PGO)ビルドのパイプラインを示したものです。静的プロファイラがプログラムの特徴量(後ほど説明します)を抽出し、機械学習モデル推論を実行してプロファイルを予測します。この予測されたプロファイルを動的プロファイリングで収集したものと同じように利用します。コンパイラがプログラム実行についての情報を使って最適化された実行バイナリを作成します。このように、機械学習モデルを使いコンパイラはプログラムを実行しなくてもプロファイルを活用できるようになり、利用にあたっての負担と、プロファイル収集に適したワークロードの探索という課題が軽減されます。

Introducing the Graal IR
静的プロファイラはプログラムのソースコード上で動作するのではなく、コンパイラの中間表現(IR)を使用して動作するという点に留意することが重要です。コンパイラはプログラムのソースコードを、より管理しやすく、冗長なコードや頻繁に繰り返されるループの削除など、さまざまな最適化に適した形式であるIRに変換します。
Intermediate Representation
https://en.wikipedia.org/wiki/Intermediate_representation
このコンテキストで、Native ImageはGraal Intermediate Representation (Graal IR) を使用してプログラムをグラフとして表現します。Graal IRは、プログラムの構造を捉え、コンパイラが高度な分析と最適化を実行できるようにする追加情報を含む高レベルのIRです。これにより、より最適化されたプログラムが生成されます。
Graal IR: An Extensible Declarative Intermediate Representation
https://ssw.jku.at/General/Staff/GD/APPLC-2013-paper_12.pdf
Graal IRは、プログラムの制御フローに対応するノードと、プログラムのデータフローに対応するノードで構成されるグラフとしてプログラムを表現します。例えば、単純なforループを考えてみましょう。Graal IRにより、制御フローのエッジを赤、データフローのエッジを青で色付けした、以下の IR グラフ(図 2)にforループが変換されます。条件 i < n を、カウンタ i の値を評価する IF ノードに解析します。ループ本体は、IRのIF制御分岐ノードのtrueブランチに対応します。したがって、ループ本体を実行することは、対応するIFノードのtrueブランチを実行することに相当します。

Graal IRの詳細については、以前のブログ投稿や論文「Graal IR: An Extensible Declarative Intermediate Representation」をご覧ください。
Under the hood of GraalVM JIT optimizations
https://medium.com/graalvm/under-the-hood-of-graalvm-jit-optimizations-d6e931394797
https://logico-jp.dev/2024/12/30/under-the-hood-of-graalvm-jit-optimizations/
Graal IR: An Extensible Declarative Intermediate Representation
https://ssw.jku.at/General/Staff/GD/APPLC-2013-paper_12.pdf
GraalSP: The Static Profiler for Native Image
静的プロファイラとGraal IRのパイプラインについて理解したところで、Native Imageにおける機械学習について説明します。弊社はNative Imageツールの一部として、正確で非常に効率的、軽量、多言語対応、堅牢な静的プロファイラであるGraalSPを開発しました。GraalSPについて、例を挙げて詳しく見ていきましょう。ヒープソート関数を使用して、(静的)プロファイリングがパフォーマンスの向上に役立つことを説明します。
Running Example: Heap Sort
以下のコードブロックに、Java Development Kit (JDK) の heapSort 関数のソースコードを記載しました。このソートの実装では、pushDownメソッドを使用して要素をヒープにプッシュしています。
/**
* Sorts the specified range of the array using heap sort.
*
* @param a the array to be sorted
* @param low the index of the first element, inclusive, to be sorted
* @param high the index of the last element, exclusive, to be sorted
*/
private static void heapSort(int[] a, int low, int high) {
for (int k = (low + high) >>> 1; k > low; ) {
pushDown(a, --k, a[k], low, high);
}
while (--high > low) {
int max = a[low];
pushDown(a, low, a[high], low, high);
a[high] = max;
}
}
Impact of the Program Profiles on Performance
関数インライン化の最適化では、forループやwhileループのループ本体が実行される可能性に基づいて、関数呼び出しをインライン化するかどうかを決定します。より正確に言えば、関数インライン化は非常に複雑な最適化であり、pushDownの呼び出しをインライン化するか否かは、ループ本体の実行の可能性のみに基づいて決定されるわけではありません。しかし、これらの可能性は、呼び出しをインライン化するかどうかを決定する上で重要な役割を果たします。したがって、heapSort関数の最適化は、forループやwhileループの実行確率に関する情報を含むプログラムのプロファイルに大きく依存します。
Inline expansion
https://en.wikipedia.org/wiki/Inline_expansion
JDK の heapSort 関数を使用して、1000万個の整数値の配列をソートすることを考えてみましょう。関数のインライン化の最適化により、pushDown メソッドへの呼び出しがインライン化され、ソート処理中の関数呼び出しのオーバーヘッドが削減されます。pushDownメソッドの呼び出しがインライン化された場合、平均のソート時間は1.80秒です。逆に、これらの呼び出しがインライン化されない場合、平均のソート時間は2.18秒に増加します。pushDownメソッドの呼び出しがインライン化されると、プログラムの実行速度が20%以上向上するため、ループ本体の実行確率は非常に重要です。
Goal: Accurately Predict Program Profiles
私たちの目的は、forループおよびwhileループの本体の実行確率を予測することです。例えば、forループに注目してみましょう。ループ本体の実行確率を予測する、というのは、Graal IRにおける対応するIFノードのtrueブランチの実行確率を予測することに相当します。したがって、私たちの目的は、forループに対応するIFノードのtrueブランチの実行確率を予測することです。そのためにはまず、Graal IR を確認し、IF ノードのブランチを「定義」する必要があります。
ML Features that Characterize Code
図3は、for ループに対応する Graal IR の IF ノード(1. Ifとします)と、制御フローグラフ (Control Flow Graph / CFG) のブロックで定義されたtrueのブランチとfalseのブランチを示しています。
Control-flow graph
https://en.wikipedia.org/wiki/Control-flow_graph
CFGについて疑問に思われるかもしれませんが、基本的にはCFGはブロックで構成されており、各ブロックにはIRグラフのノードが含まれています。CFGはGraal IRからの制御フローとデータフローの両方を統合し、プログラムの実行順序を明確に表現し、そのフローを理解しやすくします。そのため、私たちはIF文の分岐を特徴付けるためにCFGを利用しました。

IFノードのブランチを「定義」する際には、Graal IRのノードと、Graal IRを基に構築されたCFGのブロックを基準とします。1. IfノードのtrueブランチはブロックB2~B8で構成され、falseブランチはブロックB9~B24で構成されます。IFノードのブランチに対応するブロックを定義したら、IFノードを完全に特徴付けるために、IFノードをホストするCFGブロック(この例ではブロックB1)と、そのブロックを指すCFGブロック(ブロックB0)から特徴を抽出します。
抽出する特徴には、例えば、ブランチの推定アセンブリサイズ、コンピュータがそのブランチからの命令を実行する際に実行するCPUサイクルの推定回数、IFノードのネストループの深さなどがあります。このブログのスペースでは、すべての特徴について説明できません。詳細にご興味をお持ちの方は、GraalSP: Polyglot, efficient, and robust machine learning-based static profilerという論文をご覧ください。ここで重要なのは、IFノードの特徴である、trueブランチの実行確率を予測しようとする機能は、浮動小数点数のベクトルで表現されるということです。
Fermat’s last margin note. | Lapham’s Quarterly
https://www.laphamsquarterly.org/miscellany/fermats-last-margin-note
GraalSP: Polyglot, efficient, and robust machine learning-based static profiler
https://www.sciencedirect.com/science/article/abs/pii/S0164121224001031
Machine Learning for Profile Prediction
特徴ベクトルを抽出した後、機械学習モデルを訓練する教師あり学習のテクニックを使用してプロファイルを予測します。プロファイルを予測するための回帰には、XGBoost によるdecision truee (DT) モデルのアンサンブルを使用します。
Supervised learning
https://en.wikipedia.org/wiki/Supervised_learning
Introduction to Ensemble Models and XGBoost
https://medium.com/@iuyasik/introduction-to-ensemble-models-and-xgboost-9b13948a42a7
DTモデルは、ノード、ブランチ、リーフで構成されるツリー状の構造を使用してデータをモデル化します。各ノードは特徴を評価し、ツリーの下方向に決定を下します。一方、リーフノードはプロファイルを予測します。図4の左側では、IFノードのループの深さ、およびブランチのアセンブリサイズとCPUサイクル数に基づいて、trueブランチの実行確率を予測する浅いDTモデルを示しています。例えば、IFノードの深さが2以上であり、trueブランチのCPUサイクルの推定値が5未満の場合、DTモデルは当該ブランチの実行確率を0.15と予測します。DTの主な利点は、解釈可能性、速度、使いやすさです。
予測性能を向上させ、過学習を低減し、精度を高めるために、私たちは弱学習器(weak learners)としてDTを組み合わせたXGBoostアンサンブルを利用しています。図4の右側では、1,500のdecision treeで構成されるアンサンブルを示しています。アンサンブル内の各decision treeは、ターゲットブランチの実行確率を予測し、アンサンブルはすべての予測を統合(例えば平均化)して結果を決定します。
アンサンブルを使用することで、正確な予測が可能になり、decision treeを使用することで、非常に効率的な静的プロファイラを実現できます。また、軽量なdecision treeを使用することで、わずか250キロバイト程度の小さなモデルが完成します。

GraalコンパイラのIRの上に静的プロファイラを定義することで、Javaバイトコードにコンパイルされたすべてのプログラム(例えば、Java、Scalaなど)のプロファイルを予測できる多言語静的プロファイラを作成しました。
さらに、入力データが現実の Java や Scala プログラムから逸脱するシナリオに対応する、2つのプロファイル予測ヒューリスティックを設計・開発しました。もちろん、これらのヒューリスティックは機械学習モデルよりも優れたプロファイル予測を行うことはできませんが、モデルの誤りを防止できます。例えば、ヒューリスティックの1つは、ループ本体の実行確率が0.2未満にならないようにします。これにより、機械学習モデルは頻繁にループする際に重大なミスを犯すことがなくなります。生成されたプログラムのバイナリサイズをわずかに増やすことで、これらのヒューリスティックにより、異常値を効果的に処理する堅牢なスタティックプロファイラを作成できるようになりました。
静的プロファイラがプログラムのパフォーマンスに与える影響は、プログラムのコードによって異なります。その影響を評価するために、テストスイートのRenaissance、DaCapo、DaCapo con Scalaのプログラムを使用しました。
The Renaissance Benchmark Suite
https://github.com/renaissance-benchmarks/renaissance
DaCapo Benchmarks
https://www.dacapobench.org/
Da capo con scala: design and analysis of a scala benchmark suite for the java virtual machine
https://dl.acm.org/doi/10.1145/2048066.2048118
GraalSPをNative Imageに統合し、デフォルト構成と比較して実行時間を(幾何平均で)7.46%高速化しました。デフォルトのイメージビルドでは、制御分割のブランチ全体にわたって実行確率が均一に分布すると仮定しています。図5は、テストスイート別に集計したプログラムの幾何平均速度の向上率を示しています。
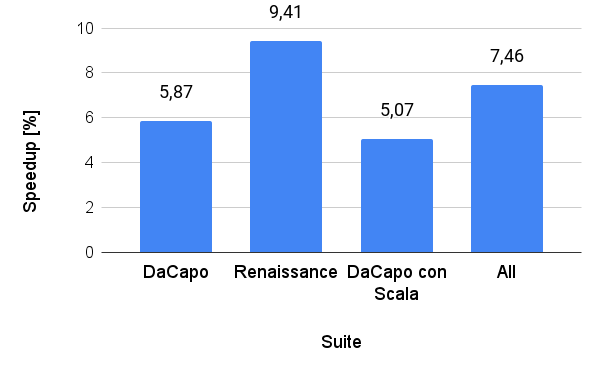
生成されたプログラムのサイズが平均でわずか3.9%増加したのと引き換えに、実行時間が改善されています。生成されたバイナリファイルのサイズが大きくなるのは、重複ベースのコンパイラ最適化によるものです。
Simulation-Based Code Duplication in a Dynamic Compiler
https://epub.jku.at/download/pdf/4410434.pdf
静的プロファイラは、通常はコードのほんの一部しか実行されないにもかかわらず、コードベース全体に対してプロファイルを生成します。重複ベースの最適化では、実行されないセクションでもコードが複製されるため、コンパイルされたプログラムのサイズがわずかに増加します。
PGOと動的に収集したプロファイルを使用して最適化されたプログラムのパフォーマンスは、GraalSPによって予測されたプロファイルを使用して最適化されたプログラムよりもはるかによい、という点は強調すべき重要なことです。 当社の実験では、PGOと動的に収集されたプロファイルを使用することで、33%高速で15%小さいプログラムが生成されました。想定通り、機械学習モデルに内在するエラーがないため、動的に収集されたプロファイルの品質は優れています。さらに、動的に収集されたプロファイルには、GraalSPが現在予測できない情報(メソッド呼び出しプロファイル、仮想呼び出しで到達した型、モニタのロックおよびロック解除の詳細など)が含まれています。もちろん、タダより高いものはないので、動的プロファイリングにはこのようなパフォーマンスの改善というメリットがあります。
Model Inference: Deployment to Production
GraalVM for JDK 17とGraalVM for JDK 20(バージョン23.0)のリリース以来、Oracle GraalVMではGraalSPがデフォルトで有効になっています。デフォルト・ビルドでは、機械学習推論プロファイル(ML-inferred profiles)を使用したPGOにより、Native Imageがプログラムを最適化することが分かるでしょう。図6は、GraalSPとNative Imageの動的プロファイリングの統合を示しています。ユーザーが動的プロファイリングを有効にすると、Native Imageがコードをインストルメント化し、インストルメント化された実行ファイルを実行してプロファイルを収集します。 動的プロファイラを有効にしない場合は、Native ImageがGraalSPを実行してプロファイルを予測し、予測値に基づいてプログラムを最適化します。
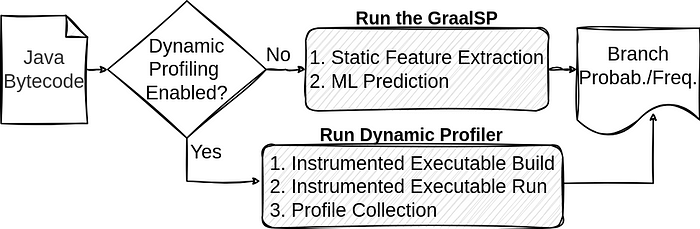
GraalSPは、Microsoftがクロスプラットフォームの高速化機械学習用に開発したONNX Javaランタイムを使用しています。これにより、Windows amd64、Linux amd64およびaarch64、Darwin amd64およびaarch64など、さまざまなアーキテクチャとの互換性が確保され、異なるプラットフォーム間でのGraalSPの柔軟性と使いやすさが実現します。また、ONNXランタイムを使用することで、コンパイル時のオーバーヘッドをわずか10%に抑えた静的プロファイリングを実装できました。
Get Started with ORT for Java
https://onnxruntime.ai/docs/get-started/with-java.html
Conclusion
まとめると、GraalSPはOracle GraalVM Native Imageでデフォルトで有効になっており、プロファイルを収集しなくてもPGOのメリットを提供します。GraalSPはGraal IRの観点でプログラムの特徴を捉え、XGBoostアンサンブルを使用してプロファイルを予測します。Native Imageは、これらの予測プロファイルを使用してPGOを実行し、最適化されたプログラムを作成します。これは、Oracle GraalVMにおける機械学習の初めての成功事例です。しかしOracle Labsでは、間もなく発表予定の、いくつかのエキサイティングなアップデート、改善、機械学習の新機能を用意しています。どうぞお楽しみに。
Oracle GraalVMの機械学習の魔法の詳細は、GraalSP: Polyglot, efficient, and robust machine learning-based static profilerをご覧ください。
GraalSP: Polyglot, efficient, and robust machine learning-based static profiler
https://www.sciencedirect.com/science/article/abs/pii/S0164121224001031
