原文はこちら。
The original article was written by Aleksandar Prokopec (Senior research manager at Oracle Labs).
https://medium.com/graalvm/stream-api-performance-with-graalvm-be6cfe7fbb52
Java 8で導入された関数型Streams APIはデータ処理するプログラムを宣言的に表現する簡潔で効率的な手法です。
Package java.util.stream
https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
しかし、ラムダ式を使用するには高度な抽象化オーバーヘッドが必要なため、Streamベースのプログラムは、低レベルのループベースのプログラムよりも実行速度が遅いことが知られています。
この記事では、具体的な例を用いて、GraalVMがStreamプログラムにおいて、Java HotSpot VMと比較して2倍から5倍のパフォーマンス向上を実現することを示します。
GraalVM
https://www.graalvm.org/
いくつかの Stream ベースのプログラムを取り上げ、GraalVMと標準のJava HotSpot VMを使用してパフォーマンスを測定し、記事の最後に、より大規模なStreamベースのプログラムの例を挙げて締めくくります。
GraalVM をダウンロードし、簡単なJMHプロジェクトをセットアップして、ご自身で測定を行ってみることもできますが、記事を理解する上で必須ではありません。
Download Oracle GraalVM
https://www.graalvm.org/downloads/
JMH
https://openjdk.org/projects/code-tools/jmh/
Setup
以下に示す例を実行したい場合は、こちらからGraalVMをダウンロードする必要があります。例を実行せずに記事だけをお読みになりたい場合は、次のセクションへお進みください。
Download Oracle GraalVM
https://www.graalvm.org/downloads/
これらのプログラムを実行するには、GraalVMのEnterprise editionを使用します。~/graalvmディレクトリにアーカイブを展開し、デフォルトのjavaコマンドとGraalVMが提供するJavaのバージョンを確認します。
$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)$ ~/graalvm/bin/java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
GraalVM 1.0.0-rc5 (build 25.71-b01-internal-jvmci-0.46, mixed mode)
次に、Mavenを使ってJMHの簡単なプロジェクトを作成します。そのため、Mavenがインストールされていることを確認してください。JMHには、ベンチマークプロジェクトを生成するためのシンプルなコマンドがあり、ソースコード用のディレクトリとしてsrc/main/javaが用意されています。
JMH
https://openjdk.org/projects/code-tools/jmh/
Welcome to Apache Maven
https://maven.apache.org/
$ mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DgroupId=org.sample \
-DartifactId=test \
-Dversion=1.0
あるいは、この記事の完全なソースコードを以下からダウンロードすることもできます。
Example Streams programs
https://github.com/axel22/streams-examples
それでは、src/main/javaにStreams.javaファイルを作成し、簡単なJMHベンチマークを記述してみましょう。このプログラムは、200万個の要素を持つ配列からストリームを作成し、いくつかのマッピング関数を使用して各数値をマッピングし、マッピングされた値の合計を求めるためにreduceを呼び出します。このプログラムで最も重要な部分はmapReduceメソッドで、以下のStream操作を呼び出します。
package org.sample;
import java.util.Arrays;
import org.openjdk.jmh.annotations.*;
@State(Scope.Benchmark)
public class Streams {
private double[] values = new double[2000000];
@Benchmark
public double mapReduce() {
return Arrays.stream(values)
.map(x -> x + 1)
.map(x -> x * 2)
.map(x -> x + 5)
.reduce(0, Double::sum);
}
}
この例を次のようにパッケージ化して実行します。
$ mvn package
Measuring Performance
標準のHotSpot JavaコマンドでmapReduceの例を実行できるようになりました。追加の-f1、-wi 4、-i4という引数は、
- JVMの1つのフォークを使用(注:JMHはプロファイルの汚染やノイズを避けるために、別のJVMプロセスで測定を行います)
- ウォームアップを4回
- 測定を4回
という設定で実行することを意味します。
$ java -jar target/benchmarks.jar mapReduce -f1 -wi 4 -i4
我々のマシン(i7-4900mq CPU、32GB RAM)では、JMHで以下の結果が得られました。
Benchmark Mode Cnt Score Error Units
Streams.mapReduce thrpt 4 38.514 ± 2.172 ops/s
HotSpot上で実行した場合、JMHはベンチマーク対象のプログラムが1秒間に約38回実行されたと報告しています。同様に、GraalVMを使用した例を次のコマンドで実行できます。
$ ~/graalvm/bin/java -jar target/benchmarks.jar mapReduce \
-f1 -wi 4 -i4
JMHの結果から、GraalVMを使った場合には1.8倍ほどのパフォーマンス改善が見られたことがわかります。
Benchmark Mode Cnt Score Error Units
Streams.mapReduce thrpt 4 69.237 ± 2.524 ops/s
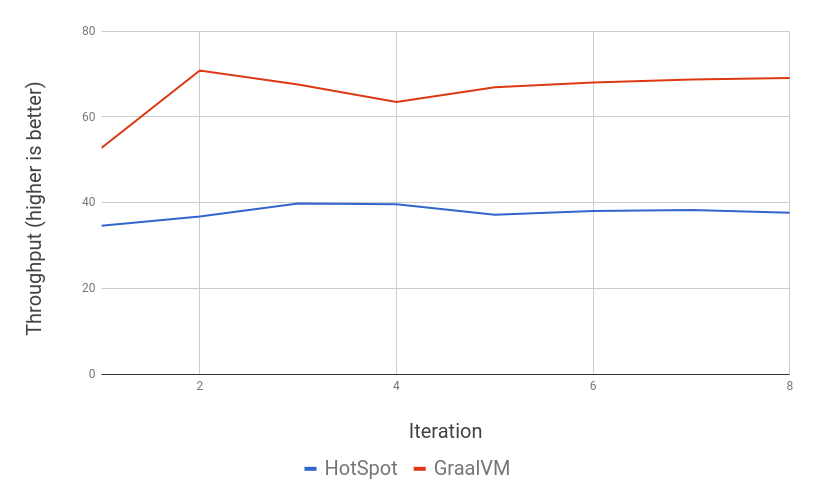
ベンチマークを少し変更して、Streamの並列化を呼び出し、その結果を測定してみましょう。
return Arrays.stream(values).parallel()
.map(x -> x + 1)
.map(x -> x * 2)
.map(x -> x + 5)
.reduce(0, Double::sum);
標準のHotSpotでは、およそ112回/秒という結果が得られました。
Benchmark Mode Cnt Score Error Units
Streams.mapReduce thrpt 4 112.904 ± 3.297 ops/s
GraalVMの場合、およそ190回/秒という結果でした。
Benchmark Mode Cnt Score Error Units
Streams.mapReduce thrpt 4 190.514 ± 4.361 ops/s
この例では、GraalVMではウォームアップが若干遅いものの、ピーク時のパフォーマンスは1.7倍となっています。

それでは、もう少し大きな例を見てみましょう。さまざまな人々のデータを保持するクラスPersonを宣言しましょう。このクラスは、特定の人物の年齢、身長、髪型を追跡します。髪型の列挙型は、髪の長さを追跡します。
enum Hairstyle {
LONG,
SHORT
}
class Person {
static final double LONG_RATIO = 0.4;
static final int MAX_AGE = 100;
static final int MAX_HEIGHT = 200;
public final Hairstyle hair;
public final int age;
public final int height;
public Person(Hairstyle hair, int age, int height) {
this.hair = hair;
this.age = age;
this.height = height;
}
}
上記のコードでは、さらにいくつかの定数を宣言しています。
LONG_RATIO:長い髪の人の割合を予想する値MAX_AGE:最大年齢MAX_HEIGHT:最大身長
をそれぞれ設定しています。これらの定数を使用して、以下に示すgeneratePeopleメソッドのように、ランダムな人々を生成します。
public static Person[] generatePeople(int total) {
Random r = new Random(10);
Person[] people = new Person[total];
for (int i = 0; i < total; i++) {
people[i] = new Person(
r.nextDouble()<LONG_RATIO ? Hairstyle.LONG : Hairstyle.SHORT,
(int)(r.nextDouble() * MAX_HEIGHT),
(int)(r.nextDouble() * MAX_AGE));
}
return people;
}
人々のデータセットに対してデータ分析を実行できるようになりました。

例えば、ショートヘアの人々のみに興味があり、その中でも若者の平均身長を計算したいとします。 若者とは、ショートヘアの人々の平均年齢より若い人々すべてと定義します。 まず、ショートヘアの人々をすべて見つけ、その平均年齢を計算する必要があります。下の図は、最初にフィルタリングする人々の集合を示しています。
次に、事前に計算した平均年齢を下回る年齢の人々のみを抽出します。これらの人々について、平均身長を計算します。これを実現するために、以下の2つのStreamパイプラインを使用します。
@Benchmark
public double shortHairYoungsterHeight() {
double averageAge = Arrays.stream(people)
.filter(p -> p.hair == Hairstyle.SHORT)
.mapToInt(p -> p.age)
.average().getAsDouble();
return Arrays.stream(people)
.filter(p -> p.hair == Hairstyle.SHORT)
.filter(p -> p.age < averageAge)
.mapToInt(p -> p.height)
.average()
.orElse(0.0);
}
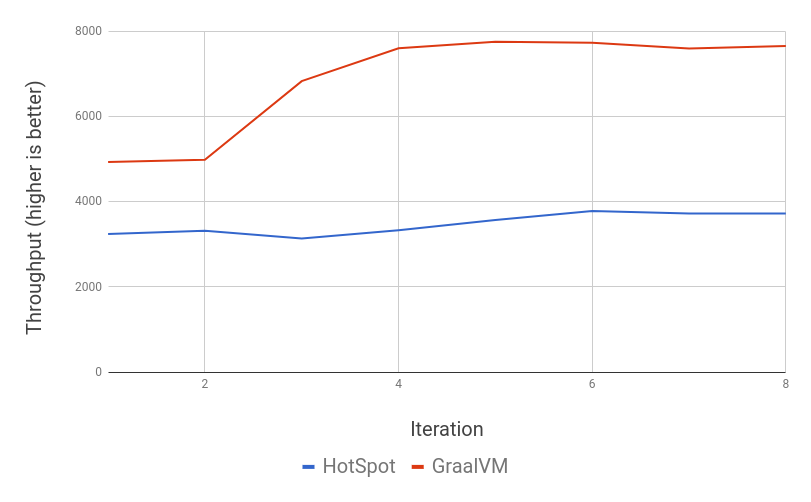
このベンチマークを実行して、パフォーマンスの数値をいくつか取得してみましょう。以下のグラフは、Java HotSpot VMとGraalVMのウォームアップ曲線を示しています。
最初のiterationでは、GraalVMは1秒あたり約5000回の反復スループットに達しますが、その後も改善を続け、HotSpotと比較して約2.1倍のスループットに達します。
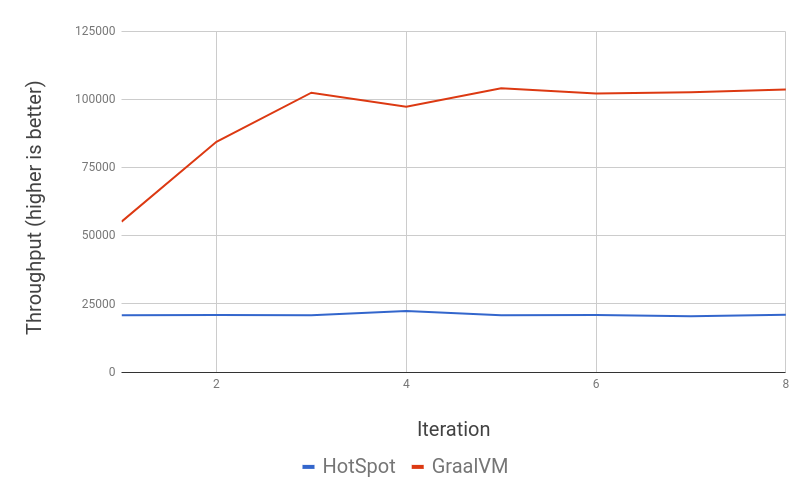
特定のケースでは、パフォーマンスの差はさらに大きくなる可能性があります。例えば、1年後にバレーボールのスター選手になる可能性のある人々をフィルタリングし、その人々の平均年齢を計算するとします。バレーボールのスター候補は、年齢が18歳から21歳で、身長が198cm以上の人と定義します(1年で身長が変わることはないと仮定します)。上図では、そのような人は3人しかいませんし、誰もがバレーボールのプロになれるわけではありません。

Streamsを使用すれば、まず各Personオブジェクトの年齢フィールドを1増やした別の Person オブジェクトにマッピングすることで、これを実現できます(1年後にバレーボールの有望選手となりそうな人々に興味があるため)。
次に、身長が198cm以上の人々をフィルタリングし、さらに年齢が18歳から21歳の人々をフィルタリングします。最後に、各 Person オブジェクトをそれぞれの年齢にマッピングし、平均を計算します。
@Benchmark
public double volleyballStars() {
return Arrays.stream(people)
.map(p ->
new Person(p.hair, p.age + 1, p.height))
.filter(p -> p.height > 198)
.filter(p -> p.age >= 18 && p.age <= 21)
.mapToInt(p -> p.age)
.average().getAsDouble();
}
このベンチマークでは、JMHによればGraalVMが5倍以上優れたスループットを出しました。
Larger example
この記事を締めくくるにあたり、これまで示した例はすべて非常に小さなプログラムであったことに注意する必要があります。これはデモ目的には有用です。なぜなら、何が起こっているかを理解しやすいからです。
しかし、GraalVMは、単純なマイクロベンチマーク以上のStreamプログラムを最適化します。これらの最適化がより大規模なStreamベースのプログラムにどのような効果をもたらすかを示すため、私たちはJose PaumardによるStreamプログラム用のオープンソースScrabbleベンチマークを取り上げ、C2とGraalを使用して実行しました。このベンチマークでは、Streamを使用して、シェイクスピアの作品から単語を選択するScrabbleソルバーを関数的にエンコードしています。
jdk8-stream-rx-comparison
https://github.com/JosePaumard/jdk8-stream-rx-comparison/tree/master/src/main/java/org/paumard/jdk8/stream
@Benchmark
public int scrabble() {
return JavaScrabble.run();
}
完全なソースコードは以下のリポジトリにあります。
Example Streams programs
https://github.com/axel22/streams-examples
GraalVMとJava HotSpot VMでこのベンチマークを実行すると、GraalVM利用時は、ピーク時のパフォーマンスに約1.9倍の差が見られました。

Conclusions
GraalVM を使用すると、Streams API を使用する Java コードをより高速に実行できます。 実際のパフォーマンス向上率は、コードやワークロードによって異なりますが、この記事のサンプル測定では、GraalVM で実行した場合、Java HotSpot VM と比較して 1.7 倍から 5 倍のパフォーマンス向上が確認されました。
GraalVMバイナリを入手して、ご自身のコードやパフォーマンステストで試してみてください。
Download Oracle GraalVM
https://www.graalvm.org/downloads/
共有したいStreams APIのサンプルが他にもあれば、ぜひお知らせください。また、GraalVMに関するフィードバックがあれば、コメント欄にご記入いただくか、GraalVMコミュニティに参加するか、Twitter(@graalvm)でメッセージをお寄せください。
GraalVM Community
https://www.graalvm.org/community/
X (a.k.a. Twitter)
http://twitter.com/graalvm
