原文はこちら。
The original article was written by Aleksandar Prokopec (Senior research manager at Oracle Labs).
https://medium.com/graalvm/under-the-hood-of-graalvm-jit-optimizations-d6e931394797
前回の記事では、GraalVMにおけるJava Streams APIのパフォーマンスをJava HotSpot VMと比較しました。GraalVMは高性能な仮想マシンであり、この実験では、GraalVM上でJava Streams APIを使用するサンプルベンチマークを実行した場合、Java HotSpot VMと比較して1.7倍から5倍のパフォーマンス向上が得られました。もちろん、正確なパフォーマンス向上は、常にコードとワークロードに依存します。そのため、確かな結論を出す前に、ぜひご自身のコードでGraalVMをお試しください。
Better Java Streams performance with GraalVM
https://medium.com/graalvm/stream-api-performance-with-graalvm-be6cfe7fbb52
https://logico-jp.dev/2024/12/29/better-java-streams-performance-with-graalvm/
GraalVM
https://www.graalvm.org/
この記事では、GraalVMがどのようにJITコンパイルを行うのか、その内部についてさらに詳しく見ていきます。
GraalVM JIT optimizations
GraalVMコンパイラが施す高度な最適化のいくつかを見てみましょう。この記事では、最も関連性の高い最適化のみを提示し、それぞれについて簡単な例を示します。さらに詳しく知りたい場合は、コレクションとStreamに対するGraalVMコンパイラの最適化の概要については、以下の論文が参考になるでしょう。
Making collection operations optimal with aggressive JIT compilation
https://www.researchgate.net/publication/320359502_Making_collection_operations_optimal_with_aggressive_JIT_compilation
https://www.davidleopoldseder.com/publications/graal_collections_authorversion.pdf
Inlining
AOTコンパイルを除けば、今日のVMで一般的なJITコンパイラのほとんどはintraprocedural analysis(プロシージャ内分析)を行っています。これは、1つのメソッド内のコードを1つずつ解析することを意味します。その理由は、intraprocedural analysisは、JITコンパイラに与えられた時間的制約では通常は実行不可能なプログラム全体に対するinterprocedural analysis(プロシージャ間分析、IPA)よりもはるかに高速だからです。プロシージャ内最適化(すなわち、1つのメソッド内のコードを1度に最適化)を行うJITコンパイラでは、インライン化は基本的な最適化の1つです。インライン化が重要なのは、メソッドを効果的に大きくできるためです。つまり、コンパイラは、これまで関連性のないメソッドにあったコードの断片間の最適化の機会をより多く見つけられるようになります。
例えば、前回の投稿で紹介したvolleyballStarsメソッドを考えてみましょう。
@Benchmark
public double volleyballStars() {
return Arrays.stream(people)
.map(p ->
new Person(p.hair, p.age + 1, p.height))
.filter(p -> p.height > 198)
.filter(p -> p.age >= 18 && p.age <= 21)
.mapToInt(p -> p.age)
.average().getAsDouble();
}
下図は、GraalVMにおけるそのメソッドの中間表現の一部を示しています。対応するJavaバイトコードから解析された直後の状態です。

Graalの中間表現(IR)は、抽象構文木(Abstract Syntax Tree / AST)のようなものだと考えていただいて結構ですが、より強力なものであり、特定の最適化をより簡単に実行できます。この中間表現がどのように機能するかを正確に理解する必要はありませんが、この表現についてさらに詳しく知りたい場合は、以下の論文が有用です。
Abstract syntax tree
https://en.wikipedia.org/wiki/Abstract_syntax_tree
Graal IR: An Extensible Declarative Intermediate Representation
https://ssw.jku.at/General/Staff/GD/APPLC-2013-paper_12.pdf
最も重要なのは、黄色のノードと赤い線で表されるメソッド内の制御フローが、Stream.filter、Stream.mapToInt、IntStream.averageなどの異なる Stream 関数を順次呼び出すことです。メソッド内のコードが正確に分からなければ、コンパイラーはこのメソッドをどのように簡略化すればよいのか分かりません。そこで、インライン化の出番です!
インライン化の変換自体は単純明快です。メソッドの呼び出しを特定し、それをインライン化されたメソッドの本体に置き換えるだけです。いくつかのメソッドをインライン化した後のvolleyballStarsのIRを見てみましょう。IntStream.averageの呼び出し以降の部分のみを表示していることに注意してください。
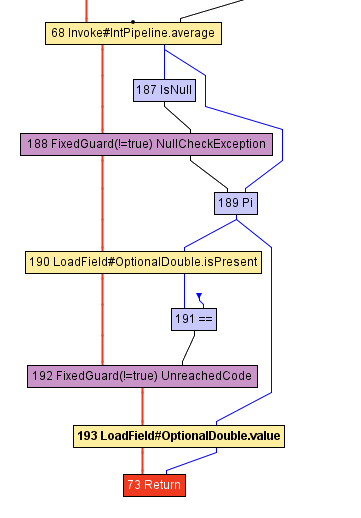
上図では、getAsDoubleの呼び出し(ノード71)が中間表現から消えていることが分かります。(volleyballStarsメソッドの最後に呼び出される)IntStream.averageが返すOptionalDoubleオブジェクトのgetAsDoubleメソッドは、JDKでは次のように定義されています。
public double getAsDouble() {
if (!isPresent) {
throw new NoSuchElementException("No value present");
}
return value;
}
上記のコード(LoadFieldノード 190)では、isPresentフィールドのロードとvalueフィールドの読み取りを特定できます。しかし、NoSuchElementExceptionの兆候や、その例外をスローするコードは見当たりません。
これは、GraalVMコンパイラがvolleyballStarsメソッドでは例外が決してスローされないと推測しているためです。通常、getAsDoubleメソッドを単独でコンパイルする場合には、このような知識は利用できません。プログラムの多くの部分でgetAsDoubleが呼び出される可能性があり、それらの他の呼び出しに対して例外がスローされる可能性があるからです。しかしvolleyballStarsメソッドでは、潜在的なバレーボールのスター選手の集合は空ではないため、例外がスローされる可能性は低いでしょう。このため、GraalVMは分岐を削除し、推測が誤っている場合はコードを非最適化するFixedGuardノードを挿入します。この例はかなり最小限のものであり、インライン化が他の最適化を可能にする方法については、はるかに複雑な例が数多くあります。
一般的に、プログラムのコールツリーは非常に深い、あるいは無限に深い可能性があり、インライン化はどこかで停止しなければなりません。インライン化には時間とメモリの制限があるからです。この点を考慮すると、いつ、何をインライン化するかという判断は、決して容易なものではありません。
Polymorphic inlining
インライン化は、コンパイラがメソッド呼び出しの正確な対象を決定できる場合にのみ機能します。Javaコードでは、通常、間接的な呼び出しが数多く発生します。つまり、実装が静的に不明なメソッドへの呼び出しであり、virtual dispatch(仮想ディスパッチ)を使って実行時に解決されます。
例として、IntStream.averageメソッドの実装を考えてみましょう。その基本的な実装は次の通りです。
@Override public final OptionalDouble average() {
long[] avg = collect(
() -> new long[2],
(ll, i) -> { ll[0]++; ll[1] += i; },
(ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; });
return avg[0] > 0 ?
OptionalDouble.of((double) avg[1] / avg[0]) :
OptionalDouble.empty();
}
しかしながら、その見た目のシンプルさに惑わされてはいけません。このメソッドはcollectの呼び出しの観点で実装されており、すべてのマジックが起こります。collectを深く掘り下げていくと、このメソッドのコールツリー(すなわち、コール階層)が急速に拡大していきます。下図のシーケンスをご覧ください。

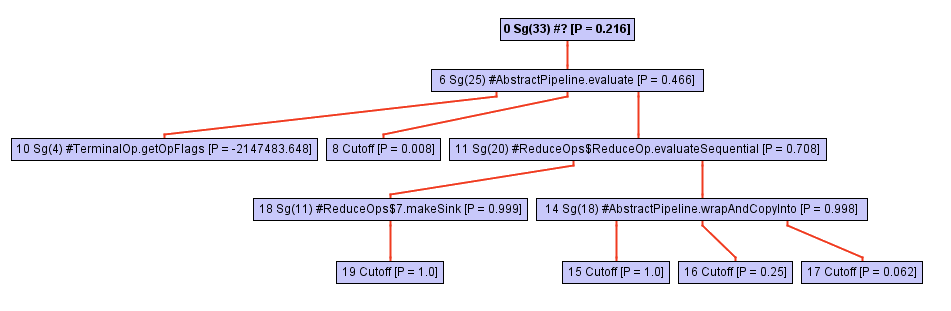
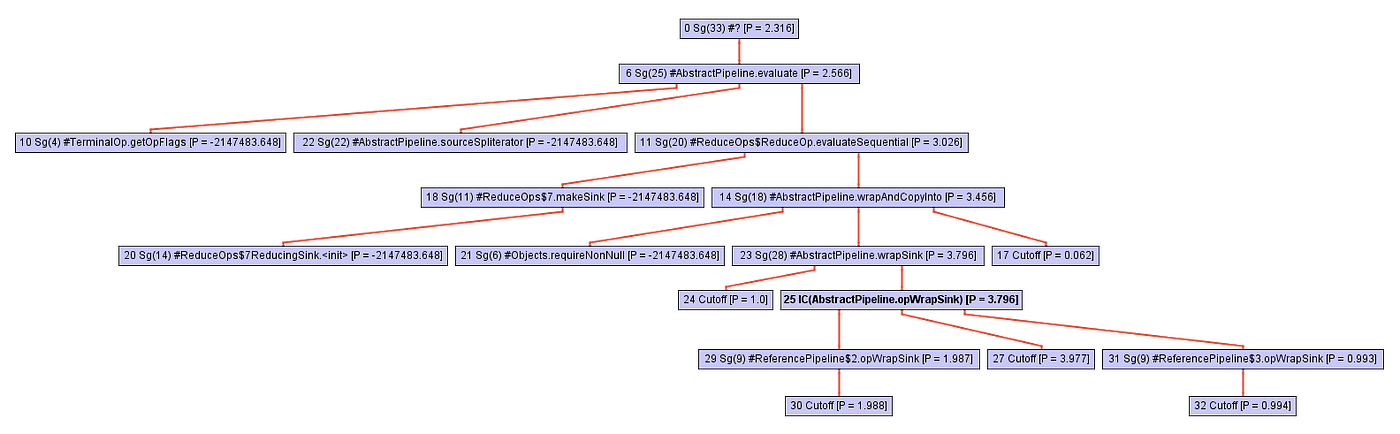
コールツリーを探索しているうちに、ある時点でインライン化機能(inliner)は、StreamフレームワークからのopWrapSinkという抽象メソッドへの呼び出しに遭遇します。
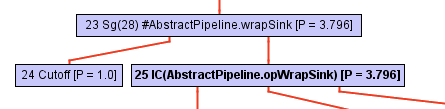
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
通常、この時点でインライン化は進められません。なぜなら、呼び出しが直接ではないためです。ターゲットの解決はプログラムの実行中に発生するため、インライン化する対象がインライン化機能ではわからないためです。
しかし、GraalVMは直接呼び出しではないすべてのコールサイトについて、レシーバータイププロファイルを維持しています。このプロファイルは、本質的には、wrapSinkの実装がそれぞれ何回呼び出されたかを表すテーブルです。今回の場合、プロファイルは、匿名クラス ReferencePipeline$2、 ReferencePipeline$3、 ReferencePipeline$4 に存在する3個の異なる実装を認識しています。これらの実装は、それぞれ50%、25%、25%の確率で発生します。
0.500000: Ljava/util/stream/ReferencePipeline$2;
0.250000: Ljava/util/stream/ReferencePipeline$4;
0.250000: Ljava/util/stream/ReferencePipeline$3;
notRecorded: 0.000000
この情報はコンパイラにとって非常に重要です。なぜなら、これはtypeswitch(実行時にメソッドの型をチェックし、それぞれの場合に具体的なメソッドを呼び出す短いswitch文)の実行を可能にするからです。中間表現の次の部分では、レシーバの型が ReferencePipeline$2、ReferencePipeline$3、ReferencePipeline$4のいずれかであるかをチェックするtypeswitch(3個のIfノード)があります。それぞれのInstanceOfのチェックの成功分岐における直接呼び出しは、それぞれインライン化でき、他の最適化も可能です。いずれの型にも一致しない場合は、Deoptノードによってコードの最適化を解除します(あるいは、代わりに仮想ディスパッチが発生します)。
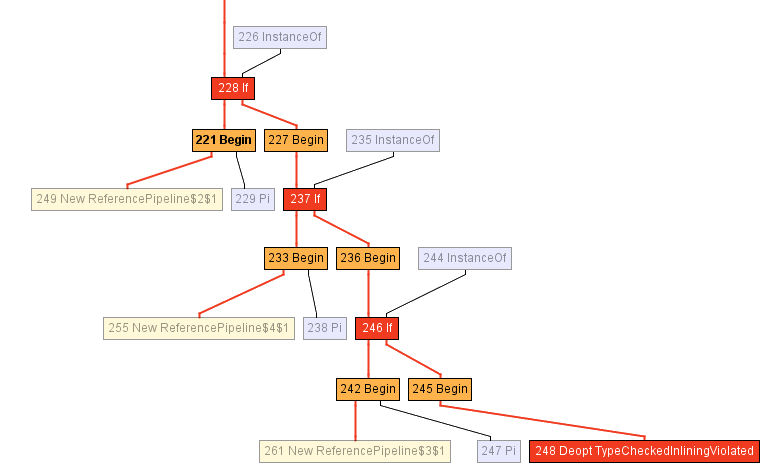
多態インライン化についてさらに詳しく知りたい場合は、このトピックに関する以下の古典的な論文をお勧めします。
Inlining of Virtual Methods
https://dl.acm.org/doi/10.5555/646156.679839
https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=8e7935654fc142ab554510e53a32e77f7d75636b
Partial escape analysis
バレーボールの例に戻りましょう。 map関数に渡されたラムダ式に割り当てられたPersonオブジェクトは、いずれもvolleyballStarsメソッドのスコープ外に出ることはありません。 言い換えれば、volleyballStarsメソッドが返るまでに、割り当てられたPersonオブジェクトを指すライブメモリの部分は存在しません。特に、これらの新しいオブジェクトへのgetHeight値の書き込みは、その後、人の身長をフィルタリングするためにのみ使用されます。
volleyballStars メソッドのコンパイルの過程で、ある時点で以下の中間表現に到達します。Beginノード 1621で始まる aブロックは、(Allocノードにおける)Personオブジェクトの割り当てから始まり、ageフィールドの値を1増やし、以前のheightフィールドの値で初期化します。heightフィールドは、LoadFieldノード1539で事前に読み込まれています。割り当ての結果はAllocatedObject(ノード2137)にカプセル化され、acceptメソッド(ノード1625)の呼び出しに転送されます。この時点でコンパイラが実行できることは他にありません。コンパイラの観点では、オブジェクトは事実上volleyballStarsメソッドから抜けます。
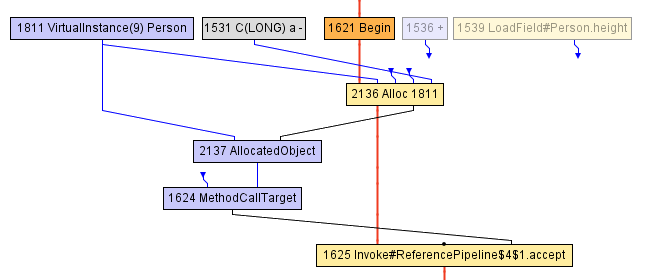
その後、コンパイラはacceptへの呼び出しをインライン化することを決定します。これは、インライン化が有用である可能性があると判断したためです。その結果下図のようなIRに到達します。

この時点で、JITコンパイラはpartial escape analysis optimization(部分エスケープ解析最適化)を実行します。AllocatedObjectノードがheightフィールドを読み取るためにのみ使われていることにコンパイラが気づきます(フィルタ条件では、このheightが198より大きいかどうかを確認するために使われていることを思い出してください)。したがって、コンパイラはheightフィールドの読み取り(ノード2167)を、以前にPersonオブジェクト(Allocノード2136)に書き込まれたノード、つまりLoadFieldノード1539に直接ポイントするように書き直すことができます。さらに、Allocノードはこの時点では他のノードへの入力として使用されていないため、単純に削除することができます。つまり、これは使われないコードです。
実は、この最適化こそが、volleyballStarsの例でGraalVMで5倍の高速化が実現する主な理由です。全てのPersonオブジェクトは作成後、すぐ破棄されますが、それでもヒープ上に割り当てる必要があり、そのメモリの初期化が必要です。部分エスケープ解析により、割り当てを排除したり、オブジェクトが実際にエスケープするコードの分岐にオブジェクトの割り当てを移動することでオブジェクトの割り当てを遅延させたりできます。
部分エスケープ解析の仕組みについては、以下の論文で詳細の説明がなされています。
Partial Escape Analysis and Scalar Replacement for Java
https://www.ssw.uni-linz.ac.at/Research/Papers/Stadler14/Stadler2014-CGO-PEA.pdf
Summary
この記事では、GraalVMの最適化機能の一部であるインライン化、多態インライン化、部分エスケープ解析について見てきましたが、他にもloop unrolling(ループ展開)、loop peeling、path duplication、strength reduction、global value numbering、constant folding(定数畳み込み)、dead code elimination(デッドコードの除去)、conditional elimination(条件付き除去)、branch speculation(分岐予測)など、数多くの機能があります。
GraalVMの動作についてさらに詳しく知りたい場合は、Publicationのページをご覧ください。また、GraalVMがアプリケーションのパフォーマンスを向上できるかどうかを確認したい場合には、GraalVMバイナリをウェブサイトから入手してお試しください。
Academic Publications
https://www.graalvm.org/latest/community/publications/
Download Oracle GraalVM
https://www.graalvm.org/downloads/
