原文はこちら。
The original article was written by Thomas Schatzl (OpenJDK developer, Oracle).
https://tschatzl.github.io/2025/02/21/new-write-barriers.html
Garbage First (G1) コレクターのスループットは、他のHotSpot VMコレクターのスループットに比べると、最大20%ほど劣る場合があります(例:JDK-8253230やJDK-8132937)。この違いは、G1がレイテンシとスループットのバランスをとり、ポーズタイムの目標を達成しようとするGCであるという原則によるものです。その大部分は、GCとアプリケーションの同期が正常な動作に必要であることに起因します。JDK-8340827で、スループットへの影響を大幅に低減するために、この同期の動作方法を大幅に再設計しました。本記事では、これらのかなり根本的な変更について説明します。
[JDK-8253230] G1 20% slower than Parallel in JRuby rubykon benchmark
https://bugs.openjdk.org/browse/JDK-8253230
[JDK-8132937] G1 compares badly to Parallel GC on throughput on javac benchmark
https://bugs.openjdk.org/browse/JDK-8132937
[JDK-8340827] G1: Improve Application Throughput with a More Efficient Write-Barrier
https://bugs.openjdk.org/browse/JDK-8340827
より詳しい情報は、対応するJEPドラフトと実装PRを参照してください。
[JDK-8340827] G1: Improve Application Throughput with a More Efficient Write-Barrier
https://bugs.openjdk.org/browse/JDK-8340827
Background
G1はインクリメンタルGCです。GC実行中、多くの時間を費やして、アプリケーション・ヒープ(以下では単にヒープ)の領域で生存オブジェクトへの参照を見つけ出してそれらを退避させるようとします。最も単純で、おそらく最も遅い方法は、退避対象ではないヒープ全体をスキャン(参照の有無を調べる)することでしょう。Hotspotのstop-the-world GCであるSerial、Parallel、G1では、原則としてCard Markingと呼ばれるかなり古い手法を採用し、GCポーズ中に参照をスキャンする領域を限定しています。
A Fast Write Barrier for Generational Garbage Collectors by Urs Hölzle, 1993
https://bibliography.selflanguage.org/_static/write-barrier.pdf
停止時間の目標をより確実に達成するために、G1ではこのカードマーキングの仕組みを拡張しました。
- アプリケーションと並行して、G1はアプリケーションがマークしたカードを再調査(改良)し、分類します。この分類により、GCポーズ中に、特定のGCにとって重要なカードのみをスキャンすればよくなります。
- アプリケーションにコンパイルされた追加のコード(書き込みバリア、write barrier)により、不要なカードのマークが削除され、スキャンするカードの量がさらに削減されます。
これは、次のセクションで示すように、追加のコストを伴います。
Card Marking in G1
Card Markingはヒープを”カード”と呼ばれる固定サイズのチャンクに分割します。各カードはカードテーブル (card table) と呼ばれる別の固定サイズの配列にバイトとして表現されます。各エントリはヒープ内の小さな領域、通常は512バイトに対応します。カードはマーク付きまたはマークなしのいずれかであり、マークはカードに対応するヒープ内に関心のある参照が存在する可能性があることを示します。GCにとって関心のある参照とは、GC対象とならないヒープ内の領域から、GC対象となる領域への参照を指します。
アプリケーションがオブジェクト参照を変更すると、アプリケーションにコンパイルされた追加のコードであるライトバリアが変更を中断し、card table内の対応するカードにマークを付けます。
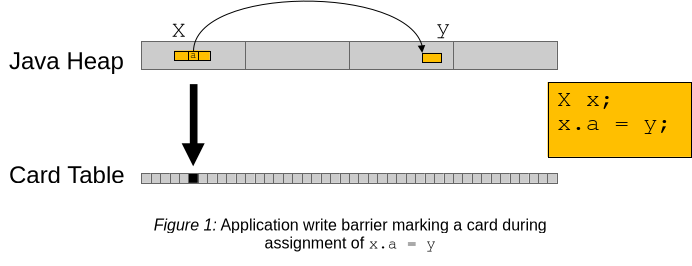
a in an object x of type X with a value of y. After writing the value into the field, the write barrier code (to be exact, post write barrier code, i.e. code added after setting the value) marks the card. (X型のオブジェクトxのフィールドaに、値yを仮想的に割り当てた実行例を示す。フィールドに値を書き込んだ後、書き込みバリアコード(正確にはpost write barrierつまり書き込みバリア後コードで、値の設定後に追加されたコード)がカードにマークを付ける。)
シリアルGCおよびパラレルGCはここで処理を停止します。GC実行まで、アプリケーションはカードにマークを付け続けます。その時点で、マーク付きカードに対応するヒープのすべてを、退避領域への参照についてスキャンします。ほとんどのアプリケーションでは、労力的にはこれで問題ありません。GC中にスキャンが必要なユニークなカードの数は非常に限られているからです。しかし、他のアプリケーションでは、カードに対応するヒープのスキャン(カードのスキャン)に、GC全体の時間のうちでかなりの割合を占める時間を費やす場合があります。
G1では、GCポーズ中のカードのスキャン回数を減らそうと、いくつかの手段を講じています。その1つ目は、アプリケーションのクリア、再調査、およびカード・マークの分類を並行して実行する追加のGCスレッドを使用する、というものです。
- 参照はGC間に再三書き込まれることがよくあるからです。参照の書き込みで生じたカードマークは、次のGCが発生するまでに、関心のある参照を含まない可能性があります。
- カードマークをその発生元に従って分類することで、GC中に、この特定のGCに関連するマーク付きカードのみをスキャンできます。
Figure 2、3、4は、この再調査(改良)プロセスについての詳細を示しています。

0xabc) in an internal buffer (refinement buffer) shown in green so that the re-examination garbage collector threads (refinement threads) can later easily find them again.(Figure 2では、前述の実際のカードマークに加えて、書き込みバリアがカードの位置(この場合は0xabc)を緑色で示した内部バッファ(refinement buffer)に格納(キューに追加)して、再検査用GCスレッド(refinement threads)が後で簡単にそれらを見つけられるようにしていることを示している)
カードスキャンのためのポーズ時の利用可能な時間と、アプリケーションがカードのマークと再検査までの間に新規でマークされたカードを生成する速度に基づいて、人為的な遅延が設定されます。この遅延により、同じカードに繰り返しマークを付けるアプリケーションのオーバーヘッドが軽減され、同じカードを繰り返し再検査目的でキューに入れなくてよくなります(すでにマークされているため)。また、この遅延により、カード自体の参照がもはや関心の対象外の可能性が高くなります。
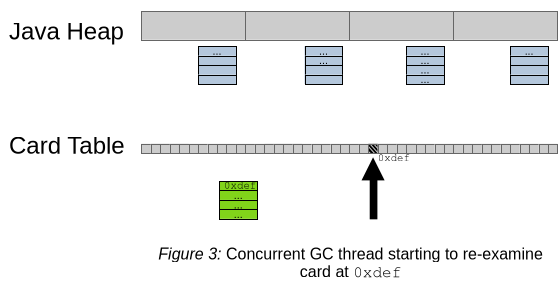
次のステップでは、Figure 3に示されているように、refinement threadが以前にキューに入れられたカードを再調査のために取り出します。この例では、0xdefの位置にあるカードが再検査対象です。図では、記憶集合 (remembered sets) も水色で示されています。すべての領域を退避させる際に、G1は、その領域で関心のあるカードの位置の集合を保存します。この図では、すべての領域にこのような記憶集合が添付されていますが、一部の領域には現在、記憶集合がない場合もあります。また、ヒープ内の領域は連続していない場合もあります(JDK-8343782およびJDK-8336086)。 また、refinement threadは、ヒープ内の対応する内容を確認する前に、カードのマークを解除します。
[JDK-8343782] G1: Use one G1CardSet instance for multiple old gen regions
https://bugs.openjdk.org/browse/JDK-8343782
[JDK-8336086] G1: Use one G1CardSet instance for all young regions
https://bugs.openjdk.org/browse/JDK-8336086
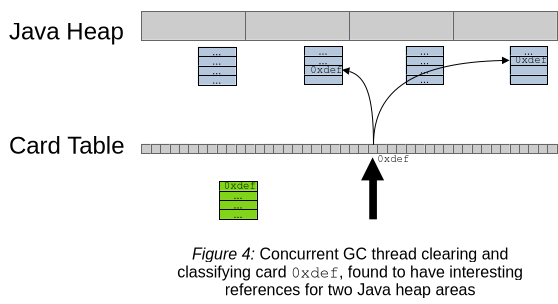
最後に、Figure 4は、refinement threadが検査したカード(0xdef)を、その時点でそのカードが関心のある参照を含む領域の記憶集合に格納するステップを示しています。カードがカバーするヒープには複数の関心のある参照が含まれる可能性があるため、複数の記憶集合がその特定のカードの場所を受け取ることがあります。
このかなり複雑なプロセスの最終結果は、Hotspot VMの他のスループット・コレクターと比較すると、ガベージ・コレクションの停止中、G1だけが2個のソースからのカードをスキャンすればよいのです。
- アプリケーションが最近dirtyとマークしたが、まだ再検査されていないカード
- 記憶集合から収集されようとしている領域の、記憶集合由来のカード
G1は、この2つのソースをマージし、記憶集合のカードをcard tableにマークしてから、カードのマーク目的でcard tableをスキャンします。[JDK-8213108]。
[JDK-8213108] Improve work distribution during remembered set scan
https://bugs.openjdk.org/browse/JDK-8213108
アプリケーションによっては、通常のカードのマーク付けと比較して、GC中のカードのスキャンにかかる時間が大幅に短縮される場合があります。
Write Barrier in G1
バリアは、アプリケーションとVMの間を調整するために実行される小さなコードの断片です。GCは、メモリの変更をインターセプトするためにバリアーを積極的に使用します。シリアル、パラレル、G1 GCは、参照への書き込みに書き込みバリアを使用します。VMはその書き込みの近辺で追加のコードを実行します。

上図は可視化したものですが、フィールドx.aに値yを書き込む場合、実際の書き込みに続いて、ガベージコレクタとの同期に使用される、書き込みとは無関係のコードが実行されます。シリアルGCとパラレルGCには書き込み後バリア(post-write barrier)しかありませんが、G1は書き込み前と書き込み後の両方のバリア(pre-write barrierとpost-write barrier)があります。G1は、この議論とは無関係な事柄のために書き込み前バリアを使っているので、以下の文章では単に「書き込みバリア」または単に「バリア」という表現を使用します。
前節では、G1における書き込みバリアの責任について説明しました。
- カードをdirtyとマーク
- カードがまだマークされていない場合、カードの位置をrefinement bufferに格納
これは簡単なように聞こえますが、図5が示すように、残念ながら複雑な問題があります。アプリケーションとrefinement threadの両方が同じカードに同時に書き込む可能性があります。前者がマークしたら後者がクリアするかもしれません。この結果、記憶集合の更新が失われる可能性があります。このような場合、再検査スレッドはカードのマークを観察しますが、追加の予防措置がなければ値の書き込みがわからないでしょう。実際、この場合には、書き込みバリアでかなりコストのかかるメモリ同期が必要になります。

さらに、カードの同時再検査は高コストになる可能性があります。特に利用可能な余分な処理リソースがない場合にはなおさらです。そのため、G1バリアには、カードマークを回避するための余分なフィルタリングコードが含まれています。このコードは、参照書き込みによって生成されるもので、GCにとって何の違いもありません。
以下の条件では、G1書き込みバリアはカードにマークしません。
- 参照の割り当てが、領域を横切らない、関心の対象外の参照を書き込んだ場合。
- コードが null 値を割り当てた場合。これらはオブジェクト間のリンクを生成しないので、対応するマーク付きカードは必要ありません。
- カードがすでにマークされている場合。それはすでに再検査がスケジュール済みであることを意味します。
Figure 6 は、結果の書き込みバリアのサイズを比較したものです。左側は、G1書き込みバリアの直接インライン化された部分(ここでは示していませんが、まれに実行される追加部分があります)、右側はシリアルおよびパラレルGC書き込みバリア全体です。
Throughput Barrier Exploration for the Garbage-First Collector (by Jevgēnijs Protopopovs, 2023)
https://ssw.jku.at/Teaching/MasterTheses/Protopopovs/Thesis.pdf

詳細は省きますが、G1書き込みバリアは3個の命令(x86-64)ではなく、約50個の命令が必要です。G1書き込みバリアの左側の棒は、上記のタスクにほぼ対応しています。青がフィルタ、緑がメモリ同期と実際のカードマーク、オレンジが再検査スレッド用の再検査バッファへのカードの格納です。
Impact
G1では、多くのメカニズムを備えた大きな書き込みバリアを使って、並列処理の正確性とオーバーヘッドに必要なメモリー同期のパフォーマンスへの影響を最小限に抑えようとしています。
アプリケーションのメモリーアクセスパターンがG1に備わっているメカニズムに適合せず、実際にはヒープ全体にわたってかなりランダムな参照割り当てを多数実行している場合、メモリー同期を減らすための努力はすべて無駄になります。その結果、BigRAMTesterのように、多くのカード位置が後で絞り込みを行うためにキューに入れられることになります。
[JDK-8152438] Threads may do significant work out of the non-shared overflow buffer
https://bugs.openjdk.org/browse/JDK-8152438
この書き込みバリアに適さない他の例としては、書き込みバリアをタイトループで実行するとともに、関心のある参照を含むカードマークを生成することが極めてまれなアプリケーションが挙げられます。このようなアプリケーションでは、並行した絞り込みが不要であるか、実際には実行されないためです(例:JDK-8253230)。このようなアプリケーションでは、書き込みバリアのコードのフットプリントが大きいため、コンパイラの最適化が阻害されたり、CPUリソースの不要な割り当てにより実行が遅くなったりします。
[JDK-8253230] G1 20% slower than Parallel in JRuby rubykon benchmark
https://bugs.openjdk.org/browse/JDK-8253230
A New Approach
ここまでで、card tableへの同時書き込みと、その後の絞り込みのためのカード位置の保存において正確性を保証するため、カードごとのマーク付きメモリ同期がG1書き込みバリアの大部分が必要としていることを示しました。
メモリ同期をなくすために、ZGCのダブルバッファリングされた記憶集合(JEP 439) と同様に、この新しいアプローチでは2つのcard tableを使用します。
JEP 439: Generational ZGC
https://openjdk.org/jeps/439
各スレッドのセット(application threadとrefinement thread)には、それぞれ独自のcard tableが割り当てられます。両card tableは最初、何もマークされていません。各スレッドのセットは、card table(それぞれcard tableとrefinement table)に異なる値のみを書き込み、実際のカードマーク処理中のきめ細かいメモリー同期の必要性を排除します。
以前と同様に、application card table上でカードマーク率を追跡するヒューリスティックが存在し、そのヒューリスティックが、そのcard table上でカードマークが多すぎるために次のガベージコレクションでポーズ時間の目標を達成できないと予測した場合、G1はcard tableをアプリケーションに対してアトミックにスワップします。その後、アプリケーションはcard table(以前のrefinement table)のマーク付けを継続し、その間、ガベージコレクションのrefinement threadがrefinement table(以前のapplication card table)のすべてのマークを再調査します。
これにより、G1書き込みバリアにおけるメモリの同期処理が不要になります。
さらに、マーク済みカードの検索に多大なコストがかからない場合、再検査対象のマーク済みカードの格納場所としてrefinement tableを直接使い、直接使います。
これにより、書き込みバリアのコードでrefinement bufferにカードの場所を格納する必要性と、メモリの同期処理が完全に不要になります。
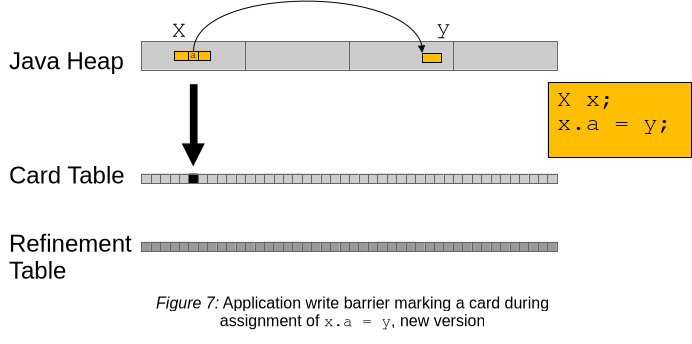
New Card Marking in G1
Figure 7は、この新しいデータ構造の配置を示しています。2つのcard tableがあり、書き込みバリアは以前と同様に、(アプリケーション)card table上のカードにマークを付けます。
card tableに十分なマークが付くと、G1 はアトミックにカードテーブルを切り替えます。Figure 8は、application card tableとrefinement tableが切り替わった直後で、アプリケーションは既に以前のrefinement table上のカードにマークを付け続けている例です。
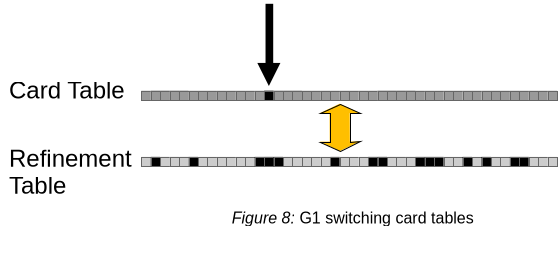
refinement threadは、前述と同様に、refinement table(以前はapplication card table)からカードの再調査を開始します。カードのマークは、マーク付きカードがすべて処理されるまで消去されます。application threadは自分のcard table上のカードにマークを付け続けるので、application threadとrefinement thread間の同期は必要ありません。
New Write Barrier in G1
少なくとも、新しいG1書き込みバリアには、Parallel GCと同様にカードマークが必要です。Parallel GCの書き込みバリアとは異なり、card tableのベースアドレスはcard tableが切り替わるたびに変更されるため、一定ではありません。そのため、Parallel GCではcard tableのアドレスをコードストリームにインライン化できますが、G1ではスレッドローカルストレージから毎回再ロードする必要があります。
現在のG1のpost write barrierは最終的に、フィルタと実際のカードマークに集約されます。ある代入 x.a = y に対して、VMは代入の後に以下の擬似コードを追加します。
(1) if (region(x.a) == region(y)) goto done; // Ignore references within the same region/area
(2) if (y == nullptr) goto done; // Ignore null writes
(3) if (card(x.a) != Clean) goto done; // Ignore if the card is non-clean
(4)
(5) *card(x.a) = Dirty; // Mark the card
(6) done:
(1)~(3)の行はフィルタを実装します。これらは以前とほぼ同じですが、最後のフィルタの条件が最適化のために少し変更されています。
フィルタがない場合、フィルタ付きのオリジナルの書き込みバリアと比較していくつかのregressionがありました。また、フィルタがあるとGCポーズ中にスキャンされていないカードの数と再検査対象のカードの個数が少なくなるので、フィルタは今のところ残されています。
最後に、5行目で実際にカードに「Dirty」と色値を付けています。
元のカードマーキング用紙では、カードテーブルのエントリに2つの異なる値を使用しています。すなわち、「Marked」と「Unmarked」、またはHotspot VMでは一般的に「Dirty」と「Clean」と呼ばれる色です。G1では、合計5つの色を使用しており、対応するヒープ領域に関する追加情報を格納しています。
| clean | カードには関心のある参照が含まれていない |
| dirty | カードには関心のある参照が含まれている可能性がある |
| already-scanned | このカードがすでにスキャン済みであることを示す(GC中に使用)。GCの段階的アプローチでポーズ時間をより適切に管理するために必要。 |
| to-collection-set | このカードには、次回のGC(コレクションセット、つまりこの名前の由来)で収集される予定のヒープ領域への関心のある参照が含まれている可能性がある。このコレクションセットには常にyoung世代が含まれるが、それは常にGCで収集されるため。 G1は常にyoung世代を収集するので、これらのカードはGC中に常にスキャンされるため、Refinementはこれらのカードのスキャンをスキップできる。たとえコレクションセットにない領域への参照が含まれていたとしても、これらのカードを記憶集合に追加する必要はない。実際には重複した情報を表すことになる。 事実上、一連のto-collection-setカードは、card table上の次のコレクションセットの記憶集合全体も格納し、余分なメモリを回避する。 書き込みバリアを単純に保つため、カードは「Dirty」として色付けされるだけである。参照がコレクションセット内のオブジェクトを参照しているかどうかを判断する追加のオーバーヘッドは、ここでは高価すぎる。 |
| from-remset | GC時に使用され、このカードの起源が記憶集合であり、最近マークされたカードではないことを示す。 これにより、 – 記憶されたセットからカードを区別 – まだ検査されていないカードからカードを区別 し、ヒューリスティクスで使用されるアプリケーションのカードマーキング率をより正確にモデル化できる。 |
最後の2つのカードの色のみが新しいものです。to-collection-setの色を使用することで、上記の書き込みバリアの行(3)で使用される条件を説明します。これにより、無害の競合を除外し、アプリケーションがこの値を不必要に上書きすることを回避します。
Switching the Card Tables and Refinement
card tableの切り替え処理の目的は、システム内のすべてのスレッドが、refinement tableが現在のアプリケーションのcard tableであることに同意し、その逆も同様であることを確認し、Figure 5で説明した問題の状況を回避することです。
このプロセスは、特別なバックグラウンドスレッドであるefinement control threadが開始します。このスレッドは、定期的に、次のガベージコレクションの開始時に現在推定されているカードの数が、カード検査率で与えられる再検査なしのカードの許容数を超えるかどうかを推定します。refinementが必要な場合、GCの前に完了する必要がある実際の作業を行う詳細化ワーカースレッドの数も計算します。
このrefinementラウンドは以下のフェーズで構成されています。
1. Swap references (card tableへの参照入れ替え)
これには、新たに作成されたVMスレッドとVMランタイム呼び出しが使用するglobal card tableポインタ、およびアプリケーションcard tableへの現在の参照の各内部スレッドのローカルコピーが含まれます。このステップでは、VM内部、ガベージコレクタ関連のスレッドに対して、スレッドローカルハンドシェイク (JEP 312) と類似のテクニックを使用します。
JEP 312: Thread-Local Handshakes
https://openjdk.org/jeps/312
これにより、正しいメモリの可視性が確保されます。このステップ後、VM全体が以前のrefinement tableを使用して新しいカードにマークを付け、その時点でアプリケーションによるすべてのカードへのマーク付けと参照書き込みを同期します。
2. Snapshot the heap (ヒープのスナップショットを取得して、refinement作業に関する内部データを収集)
ヒープの各領域について、スナップショットには現在の検査の進捗状況が格納されます。これにより、いつでもrefinementを再開でき、並列作業が容易になります。
3. Re-examine (sweep) the refinement table (マークの付けられたカードを含むrefinement tableの再検査(スイープ))
refinement workerスレッドは、card tableを直線的に(つまりスイープ)にたどり、ヒープのスナップショットを使用してマーク付きカードを探すためにcard tableの一部を要求します。Figure 9が示すように、refinementスレッドはマーク付きカードを再検査し、以下の結果になる可能性があります。
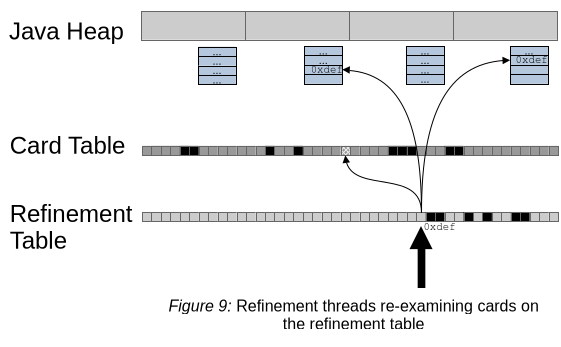
- コレクションセットへの参照を持つカードは、どの記憶集合にも追加されません。refinementスレッドは、これらのカードをapplication card tableでto-collection-setとしてマークし、それ以上のrefinementをスキップします。
- カードがto-collection-setとしてマークされている場合、refinementスレッドはカードテーブル上でこのカードを同様にマークし、対応するヒープの内容を一切検査しません。
- 現在検査できないヒープに対応するダーティなカードは、ダーティなカードとしてapplication card tableに転送されます。
- ダーティなカードに対応するヒープ領域内の関心の対象である参照が、そのカードを記憶集合に追加する原因となります。
- カードの検査中、カードは常にrefinement table上でクリーンに設定されます。
- コレクションセットに対応するrefinement tableの一部は、単純にクリアされ、再検査されません。それはこれらのカードを保持しておく必要がないためです。これらの領域の退避中、この領域の有効オブジェクトへの参照は、退避によって暗黙的に検出されます。
refinementスレッドによるapplication card tableへのへの直接書き込みは安全です。アプリケーションとのメモリ競合は軽微であり、結果は最悪でも、追加のto-collection-setカラー情報を持たない、別のダーティ・カード・マークになるからです。
4. Calculate statistics (最近のrefinementとアップデートの予測子に関する統計を計算)
これらのステップは、メモリを退避させるGCのポーズであるセーフポイントによって中断される場合があります。中断されない場合は、refinement workerスレッドは前回の終了時点のヒープスナップショットを使用してrefinementを続行します。
Garbage Collection and Refinement
refinement heuristicsは、GCによってrefinementが中断されることを回避しようとします。この場合、GCの開始時にrefinement tableは完全にマークされておらず、まだ検査されていないマーク付きカードはすべて、次のcard table scanフェーズで処理されるapplication card table上にあります。マーク付きカードをcard table上で効率的に検索できるようにするために、収集対象の領域の記憶集合をアプリケーションカードテーブルに記憶させる以外のアクションは必要ありません。
以前のG1は、すべてのマーク付きカードの位置に関する情報を保持しており、これらの位置は、記憶集合に記録されていたか、カードを絞り込むためのrefinement bufferに記録されていました。これに基づいて、G1はマーク付きカードの位置をより詳細にマップし、card table全体を検索するのではなく、マーク付きカードが置かれているエリアのみを検索できました。しかし、マーク付きカードの検索は、メモリ内の比較的小さなエリアに対する線形アクセスであるため、非常に高速です。
マーク付きカードのより正確な位置情報が存在しないことも、この情報を計算する必要がないことで相殺されます。
Young世代のヒープ領域のみを退避させる一般的なGCの場合、Young世代の領域の記憶集合はcard table上で効果的に追跡されているため、このステップでは何も行うことはありません。
refinementの任意の段階でYoung世代のGCポーズが発生した場合、GCはrefinement tableの未処理部分に対して補償作業を行う必要があります。
この場合、G1 GCはrefinementの一部を実行する新しいMerge Refinement Table(refinement tableの統合フェーズ) を実行します。
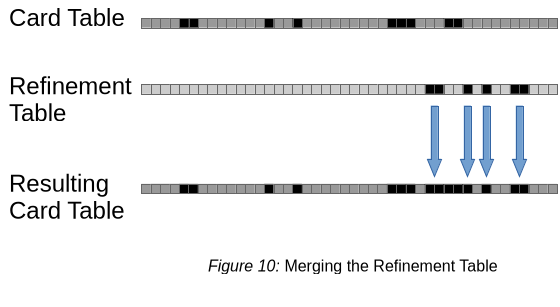
- (Optionally) Snapshot the heap as above, if the refinement had been interrupted in phase 1 of the process.
- Merge the refinement table into the card table. This step combines card marks from both card tables into the application card table. This is a logical or of both card tables. All marks on the refinement table are removed.
- Calculate statistics as above.
- (オプション)プロセスのフェーズ1でrefinementが中断された場合は、上記と同様にヒープのスナップショットを取得します。
- refinement tableをcard tableにマージします。このステップでは、両方のcard tableのカードのマークをapplication card tableに結合します。これは両方のcard tableの論理和です。refinement table上のすべてのマークが削除されます。
- 上記と同様に統計情報を計算します。
GC開始時に、refinement tableを完全にマークなしの状態にする必要がある理由は、G1が、ヒープ領域に退避されたオブジェクトのGC中に、オブジェクトが退避されたヒープ領域で関心のある参照を含むカード・マークを収集するために、refinement tableを使用するからです。これは、以前に使用されていた追加のrefinement bufferにそれらを格納するのに似ています。
young世代のGCの終了時には、2つのcard tableが入れ替えられ、新たに生成されたカードはすべてapplication card tableに移動し、refinement tableにはマークがまったく付いていない状態になります。
Full GCでは、この種のGCではこの情報が不要であるため、両方のcard tableがクリアされます。
Performance Impact
この章では、変更前と比較したスループット、(ネイティブ) メモリー使用量、およびレイテンシに関するいくつかの情報を記載します。
Throughput
結論から言うと、スループットは大幅に向上します。
- バリアにおけるきめ細かい同期が削除されたため、書き込みバリアを頻繁に実行するアプリケーションでは、スループットが大幅に向上します。もう一つの側面として、新しい書き込みバリアでは、マーク付きカードの検索が高速化(線形探索対ランダムアクセス)されたため、refinementのオーバーヘッドも大幅に削減されます。また、card table上のyoung世代の記憶集合を維持することでrefinement作業が削減されるため、ここでも節約が実現します。これらのカードは最大でも1回再調査されるだけです。
- 書き込みバリアのCPUリソースコスト(サイズ)が削減されたことで、コンパイラの最適化が改善されたか、実行が容易になったため、パフォーマンスが向上しました。
G1では、スループットの改善は使用されるヒープサイズの縮小として現れることがあります。
改善の度合いはマイクロアーキテクチャによって異なります。Parallel GCは依然としてわずかに優れていますが、この差をさらに縮めるための作業がさらに進められています。
Native Memory Footprint
追加のcard tableは、JDK 21以降と比較して、Javaヒープサイズの0.2%を占めます。 JDK 21では、card tableサイズのデータ構造が1個削除されたため、それ以前のJDKではこの違いは見られません。
追加のメモリの一部は、カード位置のrefinement bufferの削除によって相殺されます。さらに、コレクションセットの記憶集合をcard tableに保持することで、余分なスペースを必要とせずにメモリ使用量が削減されます。
これらの記憶集合のエントリを特別に色付けする最適化により、他の記憶集合に重複したエントリが表示されなくなり、ネイティブ・メモリーの利用量も削減されます。
一部のアプリケーションでは、このメモリーの削減によりcard tableの追加メモリー使用量が完全に相殺されますが、これはかなりまれなケースです。特に、young世代の大きな記憶集合を持たないアプリケーション(ほとんどがスループット重視のアプリケーション)では、前述の追加メモリー使用量が確認されます。
refinement tableは、アプリケーションがrefinementを必要とする場合にのみ必要となります。そのため、refinement tableは、すなわち、refinementがある場合のみに遅延して割り当てが可能です。このようなアプリケーションと、上記の非常にスループット重視のアプリケーションとの間には、多くの共通点があります。これは、現在のバージョンでは実装されていません。
Latency, Pause Times
ポーズ時間は、若干速くなるような傾向はないまでも、影響を受けません。一般的なケースでは、Young世代の記憶集合に対して行う作業がないため、「記憶集合をマージする」フェーズが短くなることから、ポーズ時間は通常減少します。
refinement tableをcard tableにマージする必要がある場合でも、それは非常に高速で、私の測定では常にYoung世代の記憶集合をマージするよりも高速です。この作業は、多くのランダムな書き込みの代わりに、いくつかのメモリをリニアにスキャンしているので、これは驚くほどに並列です。
GC中に作成されたカードは再変更する必要がないので、もう1つのGCフェーズが削除されました。
Summary
この変更により、細かい同期を避けるためのdual card tableアプローチを使用するG1の書き込みバリアの大部分の必要性がなくなり、アプリケーションによってはスループットが向上しています。
全体として、この変更に非常に満足しています。保守性に大きな影響を与える「G1スループット・モード」(基本的には、もう1つのGC)を導入したり、G1を不必要に複雑にしたりせずに、この問題の解決策を何年も考え、プロトタイプを作成した結果、これらのスループットバリアの利点を、あまり多くの欠点なく利用できます。
多くの人がこの変更に協力してくれました。感謝しております。
