このエントリは2025/04/01現在の情報に基づいています。将来の機能追加や変更に伴い、記載事項からの乖離が発生する可能性があります。
問い合わせ
いつもの主から以下のような問い合わせが届いた。
VNET内部モードでデプロイしたAPI Management (APIM) と、その前段にApplication Gateway (AppGW) を配置した環境がある。APMツールから監視用に実装したAPIを呼び出して外形監視している。この監視APIが連続して失敗(400以上を返す)を複数回返す場合には、すべてのAPIを閉塞して、エラーコード(例えば502)を付けて応答を返すようにしたいのだが、どうすればよいか?
具体的には以下のような感じ。この図では説明のためにApplication Insightsの標準テストで示しているが、他社サービスにも同じような仕組みがある。
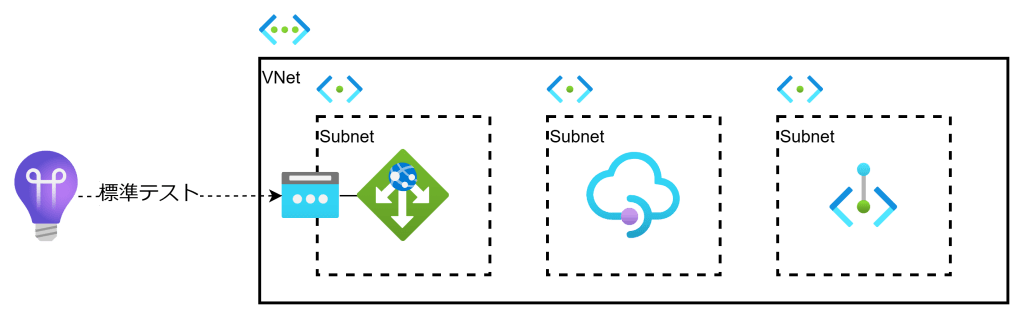
AppGWのバックエンドがAPIMのみという状況で、Application Insightsの標準テストに類するサービスの結果がよろしくない場合にAPIを閉塞できないか、ということのよう。本来は
- AppGWの正常性プローブで監視APIを指定
- 複数回の異常を検知した時点で500以上の応答を返すように構成
- 障害を通知するアラートを構成
あたりを実施すべきだが、今回は外部からAPIの応答を判断した上でやりたい、とのこと。
解決策の例
以下は解決策の例であり、唯一の解決策ではない。そして、AppGW全体を閉塞する場合と、特定のAPIのみ閉塞したい場合では方針が異なる。
1) AppGW全体の閉塞
a) AppGWから502を返せばよい場合
- 空のバックエンドプールを事前に用意
- イベント発生時に空のバックエンドプールで運用環境のバックエンドプールを置き換える
がいちばん簡単。これは、空のバックエンドプールを構成していれば、AppGWは常に502 (Bad gateway) を返す、という仕様に基づく。
標準テストの場合、アラート発呼+アクションで管理REST API(もしくはSDKを使って実装したAPIでも可)を呼び出すことで、切り替えが可能。
Application Gateways – Create Or Update
https://learn.microsoft.com/rest/api/application-gateway/application-gateways/create-or-update?view=rest-application-gateway-2024-05-01&tabs=HTTP
b) 502以外のHTTPステータスを返す必要がある場合
- 事前に所望のHTTPステータスを返すカスタム正常性プローブを作成しておく
- イベント発生時に所望のHTTPステータスを返す正常性プローブに切り替える
- AppGWの正常性プローブの動作に基づいて閉塞
という方法が考えられるが、この方法では、バックエンドの切り離し判断の閾値の設定に注意が必要。
| 1 | 瞬断のような接続失敗にも鋭敏に反応してしまう |
| 2以上 | 障害と判断してから正常性プローブによる監視間隔だけ閉塞が遅れる |
このあたりはシステム固有の要件があるはずなので、それに基づいて判断してもらうしかない。
Application Gateway の正常性プローブの概要 / Application Gateway health probes overview
https://learn.microsoft.com/azure/application-gateway/application-gateway-probe-overview
カスタム正常性プローブの作成方法は以下あたりを参照。
ポータルを使用して Application Gateway 用カスタム プローブを作成する / Create a custom probe for Application Gateway by using the portal
https://learn.microsoft.com/azure/application-gateway/application-gateway-create-probe-portal#create-probe-for-application-gateway-v2-sku
カスタム正常性プローブの切り替えには、a) と同様、管理REST APIを利用できる(もちろんAzure CLIなどを使ってもよい)。また、a)、b)とも、カスタムエラーページが必要であれば作成できる。
Application Gateway のカスタム エラー ページを作成する / Create Application Gateway custom error pages
https://learn.microsoft.com/azure/application-gateway/custom-error
2) 個別APIの閉塞
本来ならば、バックエンドサービスに対してCircuit breakerを構成し、バックエンドの状況に応じて適切なHTTPステータスを返すべきである。今回はAPMツールからの外形監視なので、呼び出した監視APIの結果に応じてAPIを閉塞するように構成する必要がある。主の案では、複数回の実行結果に基づいて障害か否かを判断する、ということなので、
- 外形監視の結果閉塞する場合には、APIMの値キャッシュに障害を示す何らかの情報を格納(シンプルに、障害時には1、そうでないときはゼロでもOK)
- 各APIはInboundセクションで上記情報をチェックし、障害時には適切なHTTPステータスを返す
- 復旧し、外形監視でも問題ないことが判明した時点で、キャッシュの値を変更
という方策を提示した。この方法はリージョンを跨ぐようなAPIMゲートウェイ配置では使えないが、今回の主はリージョンは1カ所なので問題ない。もしリージョン跨ぎの必要があれば、外部キャッシュを使ったり、外部APIの呼び出しなどを検討する必要がある(ただ、そこまで実施する必要性は十分に吟味しなければならない)。
API Management service uses a shared per-tenant internal data cache so that, as you scale up to multiple units, you still get access to the same cached data. However, when working with a multi-region deployment there are independent caches within each of the regions. It’s important to not treat the cache as a data store, where it’s the only source of some piece of information. If you did, and later decided to take advantage of the multi-region deployment, then customers with users that travel may lose access to that cached data.
API Management サービスでは、テナント単位の共有の内部データ キャッシュが使用されるため、複数のユニットにスケールアップしても、同じキャッシュ データにアクセスできます。 ただし、複数リージョンのデプロイを使用する場合、キャッシュはリージョンごとに独立しています。 キャッシュを、データの唯一の格納場所となるデータ ストアとして扱わないようにすることが重要です。 データ ストアとして扱い、後で複数リージョンのデプロイを使用することにした場合、ユーザーが移動すると、キャッシュされたデータにアクセスできなくなる可能性があります。
アーキテクチャ / Architecture
https://learn.microsoft.com/azure/api-management/api-management-sample-cache-by-key#architecture
その後
この件について後日問い合わせ主に尋ねたところ、1)-a)、つまり「AppGWの空のバックエンドプールを作成して入れ替える」という方式を採用した、とのことだった。決め手は、「一番楽」だったことのよう。
