原文はこちら。
The original article was written by Claes Redestad (Principal Member of Technical Staff, Oracle) and Per-Ake Minborg (Consulting Member of Technical Staff, Oracle).
https://inside.java/2025/03/19/performance-improvements-in-jdk24/
この記事では、JDK 23と比較したJDK 24でのパフォーマンス改善について、最も注目すべき進歩をいくつか取り上げてまとめました。トレースしやすいよう、改善点は公式 JDK Bug Systemに登録されたIssue(または下記の注で説明されているUmbrella Issue「包括的なIssue」)ごとにリストにしました。 それでは、すべて確認してみましょう。
Umbrella Issue(包括的なIssue)とは、互いに関連する複数の子のIssueから構成される親のIssueです。JDKの多くの異なる部分に影響を与える可能性がある大規模なタスクに取り組む際には、関連するissueをまとめておくことが非常に有効です。
Core Libraries
JDK-8340821 Umbrella: Improve FFM Bulk Operations
この機能強化は、Java 22で最終版がリリースされたForeign Function & Memory API(FFM API)のパフォーマンスを向上させることを目的とした一連の取り組みの一部です。この取り組みの対象のIssueは以下の通りです。
- [JDK-8338967] Improve Performance for
MemorySegment::fill
https://bugs.openjdk.org/browse/JDK-8338967 - [JDK-8338591] Improve performance of
MemorySegment::copy
https://bugs.openjdk.org/browse/JDK-8338591 - [JDK-8339531] Improve performance of
MemorySegment::mismatch
https://bugs.openjdk.org/browse/JDK-8339531 - [JDK-8339527] Adjust threshold for
MemorySegment::fillnative invocation
https://bugs.openjdk.org/browse/JDK-8339527
手短に言うと、これらのセグメントに対する一括操作は、以前はUnsafeメソッドを使って操作しており、Javaからネイティブコードへの移行が必要でした。多くの場合、移行のコストを支払えば、Javaコードよりもネイティブコードが高速ですが、より小さなセグメントの場合、ネイティブコードへの移行のコストに見合うものではないことが明らかになっています。
(fillメソッドを使用して)0xFFで埋められた小さなセグメントを作成する方法の例を以下に示します。
MemorySegment segment = arena.allocate(8).fill((byte)0xFF);
このシリーズにおけるすべての改善の背景にある考え方は、
参加セグメントが小規模であるかどうかを確認し、小規模であればネイティブコードへの移行ではなく、純粋なJavaコードを使用して一括処理を実行する
というものです。「小さな」サイズのパーティションのしきい値(これは常に2の累乗)は、妥当なデフォルト値(通常は2^6 = 64バイト)に設定されています。3つの新しいシステムプロパティにより、パーティションのしきい値をカスタム値に設定できます。以下の例では、コマンドラインパラメータを使用して、すべてのしきい値レベルを212 = 4,096バイトに増やしています。
-Djava.lang.foreign.native.threshold.power.fill=12
-Djava.lang.foreign.native.threshold.power.copy=12
-Djava.lang.foreign.native.threshold.power.mismatch=12
しきい値のpower value(指数)をゼロに設定すると、古い Unsafe-only パスが使用され、その結果、これらの拡張機能が無効になります。現在、AArch64ではMemorySegment::fillの組み込み関数の実装がないため、このプラットフォームではデフォルトのしきい値がかなり高くなっています(210 = 1,024バイト)。以下は、Linux X64 プラットフォームにおけるさまざまな小さなセグメントサイズの MemorySegment::fillレイテンシのグラフです(数値が小さいほど良い)。
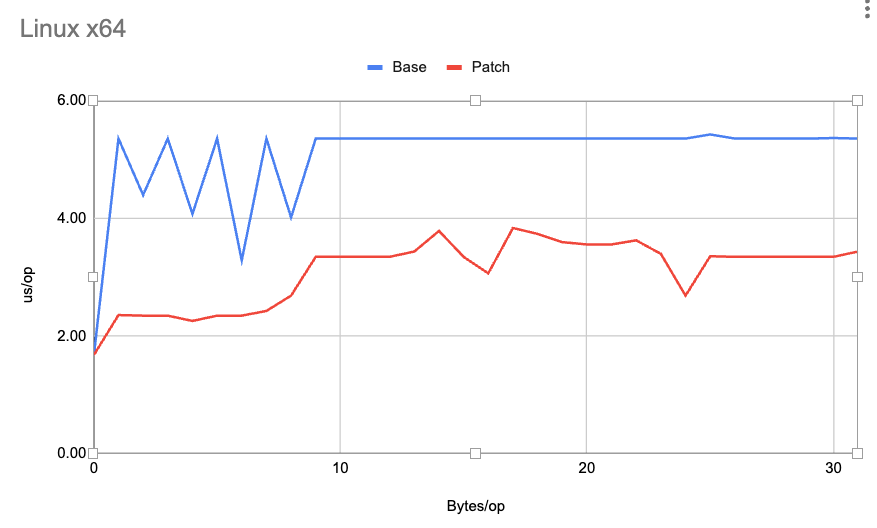
ご覧の通り、Base(古い Java-23 ブランチ)よりもPatch(改善版)の方がはるかに高速です。同様の特性は、他のすべてのサポート対象のプラットフォームおよび他の一括操作MemorySegment::copyおよびMemorySegment::mismatchでも示されています。JDK 24のプルリクエスト自体には、個々のパフォーマンス指標の概要を示す、より包括的なベンチマークとチャートのセットが含まれています。fillメソッドのPRは以下からどうぞ。
8338967: Improve performance for MemorySegment::fill #20712
https://github.com/openjdk/jdk/pull/20712
実装の詳細をさらに詳しく見てみると、新しい一括操作はjdk.internal.foreign.SegmentBulkOperationという別のクラスに移動されており、まず最初にlong、必要に応じて、続いてint、short、byteに対する操作の順に実行されていることが分かります。以下はSegmentBulkOperations::fillの抜粋です。
if (dst.length < NATIVE_THRESHOLD_FILL) {
// Handle smaller segments directly without transitioning to native code
final long u = Byte.toUnsignedLong(value);
final long longValue = u << 56 | u << 48 | u << 40 | u << 32 | u << 24 | u << 16 | u << 8 | u;
int offset = 0;
// 0...0X...X000
final int limit = (int) (dst.length & (NATIVE_THRESHOLD_FILL - 8));
for (; offset < limit; offset += 8) {
SCOPED_MEMORY_ACCESS.putLongUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, longValue, !Architecture.isLittleEndian());
}
int remaining = (int) dst.length - limit;
// 0...0X00
if (remaining >= 4) {
SCOPED_MEMORY_ACCESS.putIntUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, (int) longValue, !Architecture.isLittleEndian());
offset += 4;
remaining -= 4;
}
// 0...00X0
if (remaining >= 2) {
SCOPED_MEMORY_ACCESS.putShortUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, (short) longValue, !Architecture.isLittleEndian());
offset += 2;
remaining -= 2;
}
// 0...000X
if (remaining == 1) {
SCOPED_MEMORY_ACCESS.putByte(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, value);
}
// We have now fully handled 0...0X...XXXX
}
JITのC2自動ベクトル化(これはIncubationプロジェクトのVector APIとは異なります)の改善により、将来的には上記のコードをよりシンプルに表現でき、さらにパフォーマンスが向上することを期待しています。
JDK-8336856 Efficient Hidden Class-Based String Concatenation Strategy
hidden classを利用することで、ブートストラップ・ライブラリが内部にアクセスできるクラスを安全に定義できるようになりました。これにより、文字列連結式をより効率的に生成できるようになりました。
複雑なMethodHandleコンビネータを生成するのではなく、直接的なhidden class(アンロード不可)を構築し、それをキャッシュして異なる呼び出し元で再利用できるようになりました。これにより、直接呼び出されることのない中間的なMethodHandleインスタンスを生成する作業が大幅に削減され、クラス数やその他のランタイムのオーバーヘッドが減少します。ブートストラップして、現実的な文字列連結式のセットを使用するテストでは、この拡張機能の統合後、起動時に40%の改善が見られ、実行時のクラス生成数は約半分になりました。
8336856: Efficient hidden class-based string concatenation strategy #20273
https://github.com/openjdk/jdk/pull/20273#issuecomment-2288243097
一般的なアプリケーションでは、ピークパフォーマンスとスループットパフォーマンスは変わりませんが、アプリケーションはより高速かつ低負荷で動作するようになりました。
JDK-8333867 SHA3 Performance Can be Improved
byte配列とlong配列間の変換を減らすことで、SHA3の各種アルゴリズムは、使用するプラットフォームやアルゴリズムにもよりますが、最大27%まで改善されました。JDK-8337666で示されているように、AArch64のintrinsicの関連作業により、様々なプラットフォームで同様の改善が見られる可能性があります。
[JDK-8337666] AArch64: SHA3 GPR intrinsic
https://bugs.openjdk.org/browse/JDK-8337666
JDK-8338542 Umbrella – Reduce Startup Overhead Associated with Migration to ClassFile API
ClassFile APIはJDK 24で最終化しますが、JDK 23以降、一部のJDKライブラリコードではすでに内部的に使用されています。
JEP 484: Class-File API
https://openjdk.org/jeps/484
JDK 24では、JDK実行時にバイトコードを生成するほぼすべてのメカニズムでClassFile APIが使用され、多くの場合ASMサードパーティライブラリが置き換えられています。ClassFile APIがサードパーティ製ライブラリに採用されれば、アプリケーションは常に最新の状態に保たれる JDK 自身のバイトコード生成に依存できるようになるため、新しいJDKバージョンへの移行がよりスムーズになります。
しかし、この移行はまったく問題なく進んだわけではありません。ClassFile APIの採用により、以前に使用されていた低レベルのASMライブラリと比較して、起動、ウォームアップ、および一部のフットプリントに若干のマイナスの影響がありました。JDK 24では、多くの作業がregressionの特定と解決に費やされました。まだ多少の荒削りな部分は残っていますが、いくつかの起動テストではすでにJDK 23の数値を上回っています。また、最も顕著な起動時の問題に取り組んできた結果、他のベンチマークでも着実に改善が見られています。例えば、ClassfileBenchmark.parseでは40~50%の改善が見られました。
Runtime
JEP 491 Synchronize Virtual Threads without Pinning
以前は、virtual threadは同期中にそのcarrier threadに固定されていました。このJEPでは、synchronizedメソッドやステートメントを使用するJavaコードのスケーラビリティが向上します。これはブロックするvirtual threadが基盤となるcarrier threadを解放し、他のvirtual threadが使用できるように調整することで実現しており、これにより、virtual threadがcarrier threadに固定されるケースがほぼすべて解消されます。
Virtual threads – Threads (Java SE 23 & JDK 23)
https://docs.oracle.com/en/java/javase/23/docs/api/java.base/java/lang/Thread.html#virtual-threads
JEP 444におけるPinningに関する記載
https://openjdk.org/jeps/444#Pinning
その結果、特定の負荷に対してvirtual threadがより高速に実行されるようになり、virtual threadに対して同期ではなくロックを使用することを推奨しなくてもよくなりました。
JDK-8180450 Better Scaling for secondary_super_cache
secondary super cache (SSC) は、スーパータイプへのポインタを含むクラスに1要素のキャッシュを使用することで、instanceof式を含む特定のタイプのクエリを高速化する最適化でした。特定のワークロードでは、このキャッシュは定期的に無効化され、置き換えられます。また、ワークロードがマルチスレッド(複数のコアまたは複数のハードウェアソケットにまたがって実行)されている場合、キャッシュラインのピンポン現象により、深刻なスケーラビリティの問題が発生する可能性があります。
Are cache-line-ping-pong and false sharing the same?
https://stackoverflow.com/questions/30684974/are-cache-line-ping-pong-and-false-sharing-the-same
このpull requestでは、C2コンパイル済みコードの1要素スーパーキャッシュを完全に省略し、ハッシュテーブルの参照に完全に切り替えています。
8180450: secondary_super_cache does not scale well #18309
https://github.com/openjdk/jdk/pull/18309
ハッシュテーブルは、ポジティブなケース(happy case) では1~2サイクルの小さなオーバーヘッドですが、ネガティブなケースの参照でははるかに高速です。そして最も重要なのは、アプリケーションの実行中にハッシュテーブルが同時並行で動作するスレッドによって変更されないため、マルチスレッドアプリケーションの大幅な速度低下を完全に回避できる点です。最も一般的なプラットフォーム(Aarch64およびx64)では、これらの拡張機能はすでにJDK 23で実装されていますが、すべてのOpenJDKプラットフォームに移植されたため、JDK 24についても言及する価値があります。
- [8332587] RISC-V: secondary_super_cache does not scale well
https://bugs.openjdk.org/browse/JDK-8332587 - [8331126] s390x: secondary_super_cache does not scale well
https://bugs.openjdk.org/browse/JDK-8331126 - [8331117] PPC64: secondary_super_cache does not scale well
https://bugs.openjdk.org/browse/JDK-8331117
JDK-8320448 Accelerate IndexOf Using AVX2
この変更により、AVX2 サポート付きのx64プラットフォームにおけるString::indexOfのパフォーマンスが約1.3倍向上します。 1.3倍という数値は、少数のベンチマークタイプの平均として算出されたものです。
簡単に説明すると、String::indexOfメソッドにintrinsicコードが追加され、コンパイラがより大きなデータ単位を同時に処理できる特殊なSIMDマシンコード命令を発行できるようになりました。 これにより、特に大きな文字列の場合にパフォーマンスが向上します。
JDK-8322295 JEP 475: Late Barrier Expansion for G1
この拡張により、アプリケーションのメモリアクセスに関する情報を記録するG1ガベージコレクターのバリアの実装が簡素化されます。これは、C2 JITのコンパイルパイプラインの初期から後期へと移行することで実現しています。これにより、C2 コンパイルのオーバーヘッドが大幅に削減され、アプリケーションの起動時やウォームアップ時の JVM の時間とメモリ使用量が削減されるという目に見えるメリットがもたらされます。同様の作業は、JDK 14ではすでに ZGC に実装されています。これは、高並列処理下での正確性を確保するために必要とされていたためです。
Quest for Throughput – New Write Barriers for G1
https://tschatzl.github.io/2025/02/21/new-write-barriers.html
https://logico-jp.dev/2025/03/22/new-write-barriers-for-g1/
JEP 483: Ahead-of-Time Class Loading & Linking
JDK 24では、Ahead-of-time cache (AOTキャッシュ) が導入されました。これは2004年よりJDKの一部となっているCDSテクノロジーを徐々に改善しているものです。このAOTキャッシュは、CDSのように事前解析されたクラスの状態だけでなく、ロードおよびリンク後のクラスの状態も保存できるようになりました。これには、トレーニング実行中に多くの情報を取得する必要があります。その結果、ベースラインを徐々に改善します。
| HelloStream | PetClinic | |
|---|---|---|
| JDK 23 | 0.031 | 4.486 |
| AOT cache, no loading or linking | 0.027 (+13%) | 3.008 (+33%) |
| AOT cache, with loading and linking | 0.018 (+42%) | 2.604 (+42%) |
JEP 483は、Java言語の動的な性質を維持しながら、Javaプログラムの起動、ウォームアップ、フットプリントを改善することを目的としたProject Leydenの最初の成果物です。
JEP 483: Ahead-of-Time Class Loading & Linking
https://openjdk.org/jeps/483
Project Leyden
https://openjdk.org/projects/leyden/
今後予定されているJEPでは、JEP 483で導入されたトレーニング・ワークフローをより簡素化されたワンステップのプロセスに改善すること、プロファイリング・データとAOTコードを事前キャッシュに追加することなど、多くの改善が予定されています。
JDK-8294992 JEP 450: 4-byte Object Headers (Experimental)
この実験的な拡張により、HotSpot JVMのオブジェクトヘッダーのサイズが、64bitアーキテクチャ上で96ビットから128ビットの間のサイズから64ビットに縮小されます。これにより、ヒープサイズが縮小され、デプロイ密度が向上し、データ・ローカリティが増します。
初期の実験では、一般的なワークロードでメモリ消費量が10%から20%削減されることが期待できることがわかっています。この変更によるスループットへの影響は、ワークロードによって異なります。JEP 450を使用した性能テストの報告によると、SPECjbb2015において有望な結果(チューニングにより 4~7% の向上)が示されています。
Performance Testing for JEP 450: Compact Object Headers
https://wiki.openjdk.org/display/lilliput/Performance+Testing+for+JEP+450%3A+Compact+Object+Headers
その他のワークロードでは、性能にまったく変化が見られません(それでも、同時にメモリ使用量が削減されたのであれば良いことです)。性能をさらに向上させるための追加の改善策が検討されており、実験的な状態が解消されれば、全体的にさらに優れたベンチマーク結果が得られるでしょう。
Ports
RISC-V Improvements
RISC-Vベースのプラットフォームの分野を平準化するために、多くの労力を注いできました。RISC-Vはまだ広く使用されているわけではありませんが、この分野の参加者がこの作業に取り組んでくれたことに感謝します。これにより、真のオープンソースプラットフォームへの道が開かれました。
- [JDK-8334554] RISC-V: verify & fix perf of string comparison
https://bugs.openjdk.org/browse/JDK-8334554 - [JDK-8334397] RISC-V: verify perf of ReverseBytesS/US
https://bugs.openjdk.org/browse/JDK-8334397 - [JDK-8334396] RISC-V: verify & fix perf of ReverseBytesI/L
https://bugs.openjdk.org/browse/JDK-8334396 - [JDK-8317721] RISC-V: Implement CRC32 intrinsic
https://bugs.openjdk.org/browse/JDK-8317721 - [JDK-8317720] RISC-V: Implement Adler32 intrinsic
https://bugs.openjdk.org/browse/JDK-8317720
Other Improvements
以下に示すその他のパフォーマンス問題は、この記事では詳しく説明しませんが、JDK 24で対処済みで、Javaのパフォーマンスを維持する上で重要な役割を果たす可能性があるものです。
- [JDK-8323079] Regression of -5% to -11% with SPECjvm2008-MonteCarlo after JDK-8319451
https://bugs.openjdk.org/browse/JDK-8323079 - [JDK-8323385] Performance regression with runtime/AppCDS/applications/jetty/* tests after JDK-8324241
https://bugs.openjdk.org/browse/JDK-8323385
Conclusions and Next Steps
たくさんありましたね。この記事で取り上げたすべての変更は、Javaのパフォーマンス向上にたゆまぬ努力を続けるOpenJDKコミュニティのおかげで実現したものです。
次のステップは、実は読者の皆さん次第なのです!JDK 24をダウンロードして、実際に試してみてください。
Java Downloads
https://www.oracle.com/java/technologies/downloads/
現在お使いのバージョンと比較して、このバージョンではアプリケーションがどの程度高速化されているでしょうか?改善できる点に気づきましたか?コミュニティに参加して、Issueを上げたり、Pull requestを出したり、メーリングリストでのディスカッションに参加したりしましょう。
Java Bug System (JBS)
https://bugs.openjdk.org/
JDK repository
https://github.com/openjdk/jdk
メーリングリスト
https://mail.openjdk.org/mailman/listinfo
また、inside.javaには、Java 24のパフォーマンス改善について説明する動画があがっています。
Inside Java
https://inside.java/
Java Performance Update
https://inside.java/2025/01/26/devoxxbelgium-java-perfromance-update/
Java 24 Performance Improvements and Deprecations – Inside Java Newscast #82
https://inside.java/2024/12/12/newscast-82/
私たちの一部は、次期JDK 25リリースに向けて予定されている新たな改善策に取り組んでいます。JDK 25がリリースされた暁には、新たなパフォーマンス記事を書くことをとても楽しみにしています。
それまで、最速の道を走り続けましょう!
