原文はこちら。
The original article was written by David Kozak (PhD student at the Faculty of Information Technology Brno University of Technology and a Researcher at Oracle Labs).
https://medium.com/graalvm/skipflow-producing-smaller-executables-with-graalvm-f18ca98279c2
Point-to analysis(ポインタ解析)は、GraalVM Native Imageビルドにおける重要な要素です。
Point-to analysis / Pointer analysis
https://en.wikipedia.org/wiki/Pointer_analysis
https://ja.wikipedia.org/wiki/ポインタ解析
GraalVM Native Image
https://www.graalvm.org/latest/reference-manual/native-image/
本エントリでは、ポインタ解析の拡張機能であるSkipFlowを紹介します。SkipFlowは、分析プロセス中にプリミティブ値を追跡し、分岐条件を評価します。ベンチマーク結果では、ビルド時間を増加させずにバイナリサイズを平均6.35%削減しました。
まず、GraalVM Native Imageにおける静的解析の全体像を説明します。次に、SkipFlowがポインタ解析をどのように改善するかを説明します。最後に、実験的な評価結果を提示し、この分野における今後の研究方向について議論します。
Points-to Analysis in GraalVM Native Image
一般的なJavaアプリケーションは多くのサードパーティライブラリを使用していますが、その機能のほんの一部分しか利用していません。不要なメソッドをコンパイルしないようにするため、Native Imageはプログラム全体を対象としたポインタ解析を実施し、実行時に必要となる可能性のあるすべてのクラス、メソッド、フィールド(いわゆる「到達可能な」要素)を特定します。この文脈でポインタ解析を使用する理由を理解するため、以下の例を考えてみましょう。
void f(Iface i){
if(i == null) throw new NullPointerException();
if(i instanceof A){ ... }
i.run();
}
メソッドfのみを検査するだけでは、パラメーターiが取り得る値についてほとんど情報がありません。したがって、i.run()が Ifaceの任意のサブタイプの実装のrun()メソッドを呼び出す可能性があるため、そのようなすべてのメソッドを到達可能としてマークする必要があります。
一方、iが常に(Aのサブタイプではない)特定の型Bであり、nullではないと計算できれば、i.run()の仮想呼び出しを、型Bで利用可能なrun()メソッドの直接呼び出しに置き換えることができます。これにより、到達可能とマークされるメソッドは1つだけになります。さらに、nullチェックと型チェック(対応する分岐内のコードを含む)を削除できます。ポインタ解析は、プログラム内のすべての変数とフィールドの可能な型を追跡し、このような最適化を可能にします。ポインタ解析を採用することで、バイナリサイズが縮小され、コンパイル時間が短縮されます。
Native Image は、type flow graphと呼ばれるデータ構造を使用して解析を実行します。名前が示す通り、このグラフは、プログラム内の型の流れをモデル化します。グラフのノード(フロー)は、メソッドパラメーター、フィールド、変数、分析に関連する各種命令を表します。directed use edge(有向使用エッジ)は、ノード間で型が流れる方法を記述します。各フローは、そのフローに到達可能な型の集合を表すtypestateを保持します。
type flow graphは解析中に展開されます。ルートメソッド(例:main())のセットから始まり、追加の到達可能なコード要素が発見されるにつれ、ノードとエッジが徐々に追加されます。解析により、到達不可能なコードの削除、冗長な型チェックやヌルチェックの削除、単一のターゲットメソッドが計算されるメソッド呼び出しの仮想化解除(devirtualizing)などが可能です。上記の例では、メソッドfの内容をB.run()への直接呼び出しに簡素化できます。
ただし、我々が考慮する指標は精度だけではありません。解析はネイティブイメージのビルドごとに実行されるため、解析時間とメモリ使用量も同等に重要です。合理的な精度と高速性を両立する解析を必要としています。場合によっては、スケーラビリティを向上させるために精度を少し犠牲にすることもあります。例えば、saturationと呼ばれるテクニックを使用します。これは、変数に対して観測された型の数がある閾値(デフォルトは20)を超える場合、その変数のtype flowの追跡を細かく行わず、グラフから削除する、というものです。このテクニックは、コンパイラが通常、可能な型が少ないケースのみを最適化する点を踏まえたものです。saturationはプログラムのサイズに対して線形にスケールし、精度への影響は無視できる程度です。サチュレーションについて詳しく知りたい場合は、以下の論文を参照してください。
Scaling Type-Based Points-to Analysis with Saturation
https://dl.acm.org/doi/10.1145/3656417
Introducing SkipFlow
The analysis Native Image currently runs (which we will denote as baseline in the rest of the blog) can be needlessly imprecise on specific code patterns. Consider the example below taken from the Dacapo Sunflow benchmark.
Native Imageが現在実行している解析(以下、本エントリでは「ベースライン」と表記します)は、特定のコードパターンにおいて不要な精度不足が生じる場合があります。以下の例は、Dacapo Sunflowベンチマークから抜粋したものです。
https://github.com/fpsunflower/sunflow/blob/master/src/org/sunflow/core/Scene.java#L279
void render(..., Display display){
if (display == null) {
display = new FrameDisplay();
}
...
}
ベースライン分析では、パラメーターの表示が決してnullにならないことを確認できます。ただし、メソッドの制御フローを考慮していないため、やはり分岐の内容を分析し、FrameDisplay型がインスタンス化されているものとみなします。これ自体は大きな問題のように思えないかもしれません。しかし、変数displayの値は最終的にimageBegin()メソッドの呼び出し先のレシーバーとして使用され、FrameDisplay.imageBegin()は推移的にAWTとSwing GUIライブラリを呼び出しますが、これらのライブラリは実際には必要ありません。
これにより、多くのデッドコードを分析し、その後コンパイルすることになります。より良い方法はないものでしょうか?
静的解析の分野には、ベースライン解析の精度を向上させる多くの技術が存在しますが、これらは通常、我々のユースケースでは遅すぎます。解析はビルドごとに実行され、数分で数十万のメソッドを処理する必要があるからです。
解析の精度を向上させるために採用したアプローチのSkipFlowは、2つの主要な機能に基づいています。最初の機能は、解析実行中に分岐条件を評価することです。この機能を既存のフレームワークに実装するため、type flow graph(型フローグラフ)にpredicate edges(述語エッジ)を導入しました。このエッジは、分岐条件と分岐内のノード間の関係を表現します。上記のDacapo Sunflowの例では、displayのnullチェックを表すノードからFrameDisplayのインスタンス化を表すノードへpredicate edgeを接続します。predicate edgeが入ってくるすべてのフローはデフォルトで無効化されます。このようなフローは、use edge(使用エッジ)を使って流入する値を受け取ることはできますが、predicateによって有効化されるまで、グラフの下流に値を押し出すことはありません。これにより、分岐の内容(例えば上記のFrameDisplayオブジェクトのインスタンス化)を、実行時に分岐が実行可能であると判断されるまで評価遅延できます。Dacapo Sunflowの特定のケースでは、イメージサイズを50%以上削減できました。
もう一つの機能はプリミティブ値の追跡で、例えば以下の例のように条件が別メソッドに抽出されている場合などに役立ちます。
void onExit(Thread thread){
if (thread.isVirtual()){
virtualThreads.remove(thread);
}
}
public boolean isVirtual() {
return this instanceof BaseVirtualThread;
}
SharedThreadContainer.onExit()メソッドはJDKから継承されたもので、virtual threadsに対してのみ実行されるべきコードを含むコールバックです。
SharedThreadContainer.onExit()
https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/jdk/internal/vm/SharedThreadContainer.java#L119
このチェック自体は、単純な型チェックを含むThread.isVirtual()メソッドにオフロードされています。
これは JDK でよく使われるコードパターンです。プリミティブ値の追跡により、メソッド呼び出しの外にブール値(true と false)を伝播でき、コンパイル済みアプリケーションが実際にそれらを使用しない限り、仮想スレッド固有のコードを削除できます。
Experimental Evaluation
RenaissanceおよびDacapoベンチマークスイートおよび一連のマイクロサービスアプリケーションを使用してSkipFlowを評価しました。以下に示すのは、マイクロサービスアプリケーションの一連の例におけるバイナリサイズへの影響を示すチャートです。SkipFlowは、ビルド時間へ悪影響を与えずに、ネイティブイメージのサイズを平均4.4%削減します。実際、SkipFlowを有効にすると、分析およびコンパイル対象のメソッドが減少するため、イメージのビルド時間はむしろわずかに高速化される傾向にあります。

RenaissanceおよびDacapoベンチマークスイートでも同様の傾向が見られます。以下のチャートでご確認いただけます。
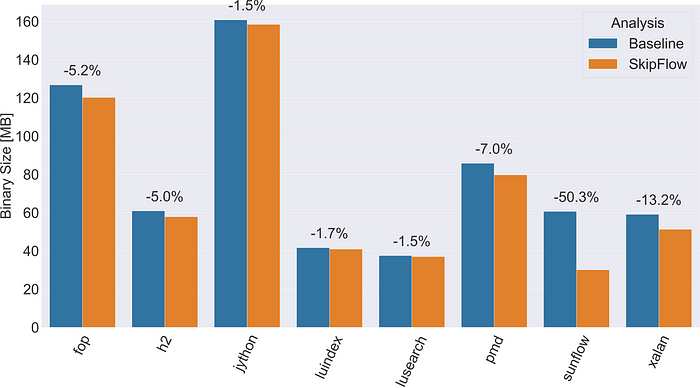

3個のベンチマークスイート全体で、バイナリサイズは平均で6.35%削減されました。評価プラットフォームは以下の通りです。
- OS: Oracle Linux Server release 7.3
- CPU: Intel Xeon E5–2630 v3 (2.40 GHz) × 2 (Cores: 8物理コア/16論理コア)
- RAM: 128 GB
- GraalVM for JDK 24
Conclusion
SkipFlowはGraalVM for JDK 24に組み込まれています。
[GR-43361] [GR-50205] Whole-Program Sparse Conditional Constant Propagation #9821
https://github.com/oracle/graal/pull/9821
ただし、デフォルトでは有効化されておらず、以下のフラグを使って有効化できます。
-H:+TrackPrimitiveValues -H:+UsePredicates
なお、SkipFlowはGraalVM for JDK 25ではデフォルトで有効化され、Early Accessビルドでは既に利用可能です。プロジェクトで試していただき、フィードバックを共有していただけると幸いです。
Early Access Builds
https://github.com/graalvm/oracle-graalvm-ea-builds/releases
今後、変数が持ち得る値の可能な範囲を含む、プリミティブ値のより正確な表現を使って、SkipFlowの分析をさらに改善する予定です。
詳細を知りたい方は、CGO’25で発表した以下の論文をご参照ください。
SkipFlow: Improving the Precision of Points-to Analysis using Primitive Values and Predicate Edges
https://dl.acm.org/doi/10.1145/3696443.3708932
