原文はこちら。
The original article was written by Claes Redestad (Principal Member of Technical Staff, Oracle) and Per-Ake Minborg (Consulting Member of Technical Staff, Oracle).
https://inside.java/2025/10/20/jdk-25-performance-improvements/
本記事では、JDK 25における数多くの注目すべきパフォーマンス改善点と機能の一部をご紹介いたします。これは決して網羅的なものではありません。JDK 25では3,200件以上の問題が修正されており、そのうち約1,000件が機能強化に該当します。このうち約100件は、明示的にパフォーマンス関連と分類されております。改善点はJDKライブラリ、ガベージコレクタ、コンパイラ、ランタイムの4つに分類し、順不同で列挙します。
Enhancements in JDK Libraries
JEP 506: Scoped Values
Scoped values APIはJDK 21でプレビュー機能として追加され、JDK 25で正式実装されました。
Scoped valuesは、ScopedValueを使って間接的に呼び出されるあらゆるメソッドに対し、暗黙のパラメータを渡すための新しい手段を提供します。これにより、現在ThreadLocalを使って同様の効果を得ているアプリケーションにおいて、パフォーマンスと柔軟性の向上が期待できます。多数のスレッド間で堅牢かつ高性能なデータ共有を可能にするためです。
エラーが発生しやすい方法であるスレッドごとの状態複製に代わって、この新しいメカニズムは任意の数のスレッド間で共有アクセスを可能にします。メモリオーバーヘッド(スレッドごとのコピーなし)が少なく、同期コストも低いため、より優れたスケーラビリティを実現します。Scoped valuesは、Virtual ThreadsやStructured Concurrencyと組み合わせて使用する場合に特に有益です。
Structured ConcurrencyはJDK 21で初めてプレビュー版として提供され、JDK 25においても引き続きプレビューAPIです(JEP 505参照)。
JEP 505: Structured Concurrency (Fifth Preview)
https://openjdk.org/jeps/505
JDK 25における更新点の一つとして、APIがScoped valuesを適切に処理するようになりました。これにより子タスクはScoped valuesを継承します。
private static final ScopedValue<String> NAME = ScopedValue.newInstance();
ScopedValue.where(NAME, "duke").run(() -> {
try (var scope = StructuredTaskScope.open()) {
// each child task can retrieve "duke" from NAME
scope.fork(() -> childTask1());
scope.fork(() -> childTask2());
scope.fork(() -> childTask3());
scope.join();
..
}
});
Nicolai Parlogが先頃Devoxx Belgium 2025でこの機能を含む多くのトピックについて解説しています。
Structured Concurrency in Action
https://inside.java/2025/10/16/devoxxbelgium-structured-concurrency-action/
JDK-8354300 Mark String.hash field @Stable
JDK 25では、String が改良され、String::hashCode 関数が定数折り畳み可能になりました。
8354300: Mark String.hash field @Stable by minborg · Pull Request #24625 · openjdk/jdk
https://github.com/openjdk/jdk/pull/24625
Constant folding
https://en.wikipedia.org/wiki/Constant_folding
これにより、String 定数を、変更不可能な定数Mapのキーとして使用するといった、一般的なシナリオにおいて、パフォーマンスが大幅に向上する可能性があります。
private static final Map<String, Foo> MAP = Map.of("constant", value, ...);
...
MAP.get("constant").foo();
このシナリオにおいて、定数折り畳みとは、JIT が Map のルックアップを完全にスキップし、そのルックアップを value.foo() への直接呼び出し、あるいはそれ以上の処理に置き換えることを意味します。StringHashCodeStatic.nonZero のような対象を絞ったマイクロベンチマークでは、これにより約 8 倍の速度向上が得られます。
StringHashCodeStatic::nonZero()
https://github.com/openjdk/jdk/blob/072b827/test/micro/org/openjdk/bench/java/lang/StringHashCodeStatic.java#L67
以下の記事では、ベンチマークや実装の詳細についてさらに詳しくお読みいただけます。
Strings Just Got Faster
https://inside.java/2025/05/01/strings-just-got-faster/
https://logico-jp.dev/2025/06/25/strings-just-got-faster/
簡単に言えば、文字列のハッシュコードは、内部の@Stableアノテーションでマークされたフィールドに格納されるようになりました。これにより、JITコンパイラは、その値がデフォルトのゼロ値でなくなった場合でも、その値を信頼して定数展開できるようになります。@StableアノテーションはJDK内部のものですが、汎用的なアプローチも現在検討されています。
JEP 502: Stable Values (Preview)
StableValueAPI(JDK 25でプレビュー公開)を使用すると、誰でも暗黙的に安定した遅延定数を宣言できます。これは、値が遅延評価された時点で、JVMがその値を定数として扱うことを意味します。計算は宣言時に指定された計算関数を使用して行われ、定数はSupplierにキャッシュされます。
class OrderController {
private final Supplier<Logger> logger = StableValue.supplier(() -> Logger.create(OrderController.class));
void submitOrder(User user, List<Product> products) {
logger.get().info("order started");
...
logger.get().info("order submitted");
}
}
上記の例では、フィールド logger は型 Supplier<Logger> ですが、生成時点ではまだ定数は初期化されていません。logger.get() を初めて呼び出すタイミングで、基盤となる計算関数 () -> Logger.create(OrderController.class) が評価され、定数が初期化されます。
定数が初期化されると、JITコンパイラはその定数が決して変化しないと確信できるため、定数のそれ以降の読み取りを省略できるようになります。つまり、定数折り畳みが行われるのです。この手法により、コードの削除を含め、大幅なパフォーマンス向上が期待できます。実質的には、これはJDK内部コードで利用可能な@Stableアノテーションと同じ効果を持ちますが、ライブラリやアプリケーションの開発者に対しても、安全かつ強制的な形で利用可能となっています。
プレビューAPIは変更される可能性がある点にご留意ください。執筆時点では、StableValueはJDK 26においてLazyConstantにリネームされる予定です。
JDK-8345687 Improve the Implementation of SegmentFactories::allocateSegment
このPanama Foreign Function and Memory(FFM)の機能強化により、ネイティブメモリセグメントの割り当てが最大2倍高速化されます。これは、メモリの明示的なアラインメント、不要なマージやオブジェクトの割り当ての回避、ゼロ化処理の改善、およびその他のいくつかの工夫によって実現されています。java.lang.foreignコンポーネントにおける共有メモリの処理が改善されたことで、ネイティブライブラリとの相互運用時のパフォーマンスが向上しました。FFMは、JEP 454のリリースに伴いJDK 22で正式に実装され、JNIを上回るパフォーマンスを発揮しつつ、ネイティブ統合を簡素化するという可能性をもたらします。Per Minborgが、この件についてより詳しくブログに記しています。
JEP 454: Foreign Function & Memory API
https://openjdk.org/jeps/454
Java 22: Panama FFM Provides Massive Performance Improvements for Native Strings
https://minborgsjavapot.blogspot.com/2023/08/java-22-panama-ffm-provides-massive.html
JDK-8354674 AArch64: Intrinsify Unsafe::setMemory
この機能強化により、I/O、デスクトップ、およびForeign Function and Memory(FFM)APIで一般的に使用されるAPIのUnsafe::setMemoryの処理を高速化するintrinsicが追加されました。提供されたマイクロベンチマークでは、java.lang.foreign.MemorySegment::fillを使用してデータのチャンクを書き込む際に、約2.5倍の高速化が確認されています。
Added Intrinsics for ML-KEM and ML-DSA API
JDK 24では、Quantum-Resistant Module-Lattice-Based Key Encapsulation Mechanism(ML-KEM)(JEP 496)およびQuantum-Resistant Module-Lattice-Based Digital Signature Algorithm(ML-DSA)(JEP 497)が追加されました。
JEP 496: Quantum-Resistant Module-Lattice-Based Key Encapsulation Mechanism
https://openjdk.org/jeps/496
JEP 497: Quantum-Resistant Module-Lattice-Based Digital Signature Algorithm
https://openjdk.org/jeps/497
JDK 25では、専用イントリンシックの導入により、AArch64およびIntel AVX-512プラットフォームにおいて、これらの新しいAPIの多くでパフォーマンスが2倍に向上しました。これにより、最新のハードウェア上でのこれらのセキュリティ操作の多くにおいて、OpenJDKはOpenSSLとほぼ同等の性能を発揮するようになりました。
- [JDK-8349721] Add aarch64 intrinsics for ML-KEM – Java Bug System
https://bugs.openjdk.org/browse/JDK-8349721 - [JDK-8351412] Add AVX-512 intrinsics for ML-KEM – Java Bug System
https://bugs.openjdk.org/browse/JDK-8351412 - [JDK-8348561] Add aarch64 intrinsics for ML-DSA – Java Bug System
https://bugs.openjdk.org/browse/JDK-8348561 - [JDK-8351034] Add AVX-512 intrinsics for ML-DSA – Java Bug System
https://bugs.openjdk.org/browse/JDK-8351034
JDK-8350748 VectorAPI: Method “checkMaskFromIndexSize” Should Be Force Inlined
低レベルライブラリでは、JITのインライン化の方法を微調整することで、重要な最適化が期待通りに実行されるように調整できます。この機能強化は、Vector APIにおけるそのような問題に対処するもので、重要な箇所でインライン化を強制的に実行することで、対象となるベンチマークにおいて14倍の高速化を実現しました。
JDK-8350493 Improve Performance of Delayed Task Handling
java.util.concurrent.ForkJoinPoolは、遅延タスクをより適切に処理できるよう、ScheduledExecutorServiceを実装するように更新されました。
この大幅な見直しにより、ロックに関連するボトルネックが解消され、特に遅延タスク(タイムアウトハンドラなど)のキャンセル時のパフォーマンスが大幅に向上しました。また、submitWithTimeoutなどの便利なメソッドも追加されました。
submitWithTimeout – ForkJoinPool (Java SE 25 & JDK 25)
https://docs.oracle.com/en/java/javase/25/docs/api/java.base/java/util/concurrent/ForkJoinPool.html#submitWithTimeout(java.util.concurrent.Callable,long,java.util.concurrent.TimeUnit,java.util.function.Consumer)
Other JDK Library Performance Enhancements and Bug Fixes
BigDecimal.valueOf(double) における冗長な String フォーマットを回避一般的な入力に対して、BigDecimal.valueOf の処理速度が 6~9倍向上します。
[JDK-8356709] Avoid redundant String formatting in BigDecimal.valueOf(double) – Java Bug System
https://bugs.openjdk.org/browse/JDK-8356709
x86 64 ビットプラットフォーム向けの Math.cbrt を最適化します。後続の修正(JDK-8358179)と合わせて、この x86 向けの機能強化により、Math.cbrt(立方根)の処理速度が 3 倍 向上します。AArch64 でも同様の変更が試みられましたが、そこでは効果が確認されませんでした。
[JDK-8353686] Optimize Math.cbrt for x86 64 bit platforms – Java Bug System
https://bugs.openjdk.org/browse/JDK-8353686
[JDK-8358179] Performance regression in Math.cbrt – Java Bug System
https://bugs.openjdk.org/browse/JDK-8358179
cbrt() – Math (Java SE 25 & JDK 25)
https://docs.oracle.com/en/java/javase/25/docs/api/java.base/java/lang/Math.html#cbrt(double)
java.lang.CharacterDataLatin1およびその他の CharacterDataクラスに @Stableおよび finalを追加しました。現時点では実環境での影響は不明ですが、これにより一部のコードで定数折り畳みが可能になる可能性があります。
[JDK-8357690] Add @Stable and final to java.lang.CharacterDataLatin1 and other CharacterData classes – Java Bug System
https://bugs.openjdk.org/browse/JDK-8357690
Garbage Collection Improvements
JEP 521 Generational Shenandoah
JDK 24で導入されたShenandoah GCの世代別モードは、JDK 25で正式な機能となりました。
JDK-8350441 ZGC: Overhaul Page Allocation
このZGCの大幅な機能強化により、ZGCのページキャッシュがマップドキャッシュに置き換えられ、ZGCによる未使用の割り当て済みメモリの管理が改善されました。マップドキャッシュは、連続したメモリ範囲からなる自己平衡二分探索木として実装されており、メモリ範囲の挿入時にそれらを統合します。これにより、とりわけヒープメモリの断片化が軽減されます。この大幅な改修によるもう一つの結果として、ZGCはマルチマップされたメモリを使用しなくなりました。これにより、報告されるRSS使用量が人為的に水増しされたように見えることはなくなります。
Joel Sikströmが、今回の大規模な改修に焦点を当て、ZGCがメモリをどのように割り当て、管理しているかについて、包括的で詳細な解説記事を執筆しています。
How ZGC allocates memory for the Java heap
https://joelsiks.com/posts/zgc-heap-memory-allocation/
JDK-8343782 G1: Use One G1CardSet Instance for Multiple Old Gen Regions
この機能により、G1はOld世代の任意の領域の記憶集合 (Remembered set) を他の領域と統合できるようになり、メモリの節約が可能になります。PRで言及されているあるGCストレステストでは、64GBのヒープを持つJVMにおいて、リメンバードセットが使用するピークメモリが2GBから0.75GBに削減されました。これは、プロセス全体の約2%に相当します。
Garbage-First (G1) Garbage Collector
https://docs.oracle.com/en/java/javase/24/gctuning/garbage-first-g1-garbage-collector1.html#GUID-1CDEB6B6-9463-4998-815D-05E095BFBD0F
8343782: G1: Use one G1CardSet instance for multiple old gen regions by walulyai · Pull Request #22015 · openjdk/jdk
https://github.com/openjdk/jdk/pull/22015
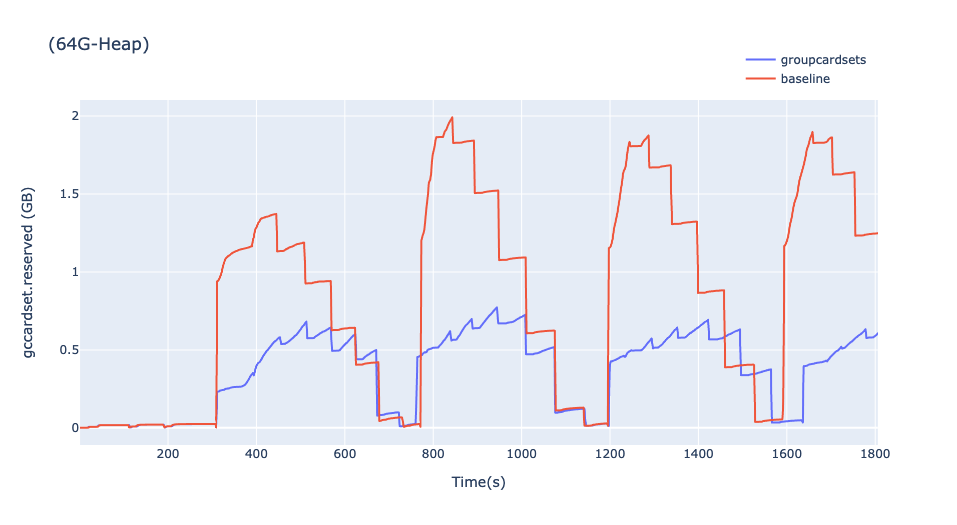
JDK-8351405 G1: Collection Set Early Pruning Causes Suboptimal Region Selection
G1は、Mixed GC中に領域を回収するためのコストをより正確に見積もるようになり、ポーズ時間に大きな影響を与える領域の回収をスキップするようになりました。その結果、特にMixed GCサイクルの終盤におけるポーズ時間の急増が抑えられ、アプリケーション全体のパフォーマンスが向上します。Thomas Schatzlが、自身のブログ「JDK 25 G1/Parallel/Serial GC changes」で、これらの変更点やその他のGCに関する変更について詳しく解説しています。
JDK 25 G1/Parallel/Serial GC changes
tschatzl.github.io/2025/08/12/jdk25-g1-serial-parallel-gc-changes.html
https://logico-jp.dev/2025/09/05/jdk-25-g1-parallel-serial-gc-changes/
JDK-8357443 ZGC: Optimize Old Page Iteration in Remap Remembered Phase
この機能強化では、既存の最適化を活用して、ページテーブル全体をスキャンせずにすべてのoldページを特定し、ガベージコレクションの対象となるページが少ない場合に、大規模なガベージコレクションの処理を高速化します。
一般的な使用状況ではわずかな改善にとどまる可能性がありますが、大規模でありながら比較的空いているヒープ上で、手動で大規模なガベージコレクションをトリガーする場合(例:System.gc()を使用する場合など)といった一部の特殊なケースでは、大幅な高速化につながる可能性があります。PRでは、4GBのヒープで最大20倍、最悪のケースの設定では16TBのヒープで最大900倍の高速化が確認されています。
8357443: ZGC: Optimize old page iteration in remap remembered phase by stefank · Pull Request #25345 · openjdk/jdk
https://github.com/openjdk/jdk/pull/25345
Compiler Improvements
JDK-8343685 C2 SuperWord: Refactor VPointer with MemPointer
これは、C2における自動ベクトル化を改善するための、より大規模な取り組みの一環です。これは、JITによって通常のJavaコードが変換され、SIMD命令を使用するようになる技術であり、これにより大幅な高速化が可能になります。
この機能強化により、より多くのパターンがこのような最適化の対象となり、大きな効果をもたらします。JVMLSでのEmanuel Peterによる講演で、この機能強化の後、以下のコードスニペットが33倍高速に実行されるようになったことをさりげなく言及しています。
for (int i = 0; i < (int)a.byteSize(); i++) {
byte v = a.get(ValueLayout.JAVA_BYTE, i + invarL);
a.set(ValueLayout.JAVA_BYTE, i + invarL, (byte)(v + 1));
}
Emanuelは、C2コンパイラにおける自動ベクトル化についてブログで詳しく解説しています。以下の入門記事は、このテーマを深く掘り下げるための良い出発点となるでしょう。
SuperWord (Auto-Vectorization) – An Introduction | Emanuel’s Blog
https://eme64.github.io/blog/2023/02/23/SuperWord-Introduction.html
JDK-8307513 C2: Intrinsify Math.max(long,long) and Math.min(long,long)
これは、Emanuel PeterのJVMLSでの講演で言及された、もう一つの自動ベクトル化の改良点です。Math.maxおよびMath.minに対して特別な処理を施すことで、これらの演算はC2による自動ベクトル化の対象とみなされるようになります。
提供されたMinMaxVectorマイクロベンチマークのクリッピング変種(Math.minとMath.maxの両方を組み合わせたもの)では、さまざまなプラットフォームにおいて3~5倍の速度向上が確認されています:
MinMaxVector.java
https://github.com/openjdk/jdk/blob/4e51a8c9ad4e5345d05cf32ce1e82b7158f80e93/test/micro/org/openjdk/bench/java/lang/MinMaxVector.java
@Benchmark
public long[] longClippingRange(RangeState state) {
for (int i = 0; i < state.size; i++) {
state.resultLongs[i] = Math.min(Math.max(state.longs[i], state.lowestLong), state.highestLong);
}
return state.resultLongs;
}
自動ベクトル化の機能向上により、明快でシンプルなJavaコードでも、最新のCPUが持つSIMD機能を活用できるようになります。
JDK-8347405 MergeStores with Reverse Bytes Order Value
JDK 23では、C2にマージストア最適化が追加され、バイト単位のストア操作を効率的な方法でより幅の広いプリミティブ型に統合できるようになりました。JDK 25では、この機能がさらに強化され、バイトが逆順で格納される場合にも同様の統合が行えるようになりました。
public void patchInt(int offset, int x) {
byte[] elems = this.elems;
elems[offset ] = (byte) (x >> 24);
elems[offset + 1] = (byte) (x >> 16);
elems[offset + 2] = (byte) (x >> 8);
elems[offset + 3] = (byte) x;
}
特定のマイクロベンチマークでは、このようなコードにおいて最大4倍の高速化が確認されています。
Intel x64やAarch64などの一般的なリトルエンディアンシステムでは、これにより、Javaがネットワーク順序(ビッグエンディアン)でデータを出力する速度が、以前よりも大幅に高速化される可能性があります。
JDK-8346664 C2: Optimize Mask Check with Constant Offset
この機能強化により、((index + offset) & mask) == 0 といったマスクチェックが、offset が定数である場合に改善されます。これにより、比較的よく見られる低レベルな式について、より多くの定数展開が可能になります。これは特定のPanamaワークロードを支援するために発見・実装されたものですが、この最適化は汎用的かつ低レベルなものです。
以下は、java.lang.foreign の使用を避けるために、PR内のものを改変したマイクロベンチマークです。
long address = 4711 << 3L;
@Benchmark
public void itsOver9000() {
for (long i = 0; i < 32768; ++i) {
if (((address + ((i + 1) << 3L)) & 7L) != 0) {
throw new IllegalArgumentException();
}
}
}
8346664: C2: Optimize mask check with constant offset by mernst-github · Pull Request #22856 · openjdk/jdk
https://github.com/openjdk/jdk/pull/22856#issuecomment-2601757857
これらの式は正しく定数展開できるようになったため、JITコンパイラはさらに一歩踏み込んだ最適化を行います。JITコンパイラは、このチェックが常に真になることを認識し、最終的にループ全体を最適化して削除します。その結果、10,000倍の高速化が実現しました。
最も高速なコードとは、そもそも実行する必要のないコードなのです。
Other Compiler Performance Enhancements and Bug Fixes
C2: Or(I|L)Node::Ideal に AddNode::Ideal の呼び出しが欠けていました。これにより、JDK 21 で発生した回帰不具合が修正されました。この不具合により、(a | 3) | 6 といった式が、期待通りに定数展開されなくなっていました。
[JDK-8353359] C2: Or(I|L)Node::Ideal is missing AddNode::Ideal call – Java Bug System
https://bugs.openjdk.org/browse/JDK-8353359
NeverBranchNode によりブロック周波数の計算が不正確になる問題無限ループのパフォーマンスに悪影響を及ぼす可能性があった問題を修正しました。
[JDK-8353041] NeverBranchNode causes incorrect block frequency calculation – Java Bug System
https://bugs.openjdk.org/browse/JDK-8353041
AMD Zen 4 向けの SIMD ソートを最適化します。AMD Zen 4 以降のプロセッサが、適切に最適化された配列ソートルーチンを使用するようにします。
[JDK-8317976] Optimize SIMD sort for AMD Zen 4 – Java Bug System
https://bugs.openjdk.org/browse/JDK-8317976
C2: MergeStores は RangeCheck スマーリングの後に実行される必要があります。前述のマージストア最適化が別の最適化と相性が悪かった一部のケースについて、その最適化を別のパスに分離することで改善します。
[JDK-8351414] C2: MergeStores must happen after RangeCheck smearing – Java Bug System
https://bugs.openjdk.org/browse/JDK-8351414
Runtime Improvements
JEP 515 Ahead-of-Time Method Profiling
Project Leydenは、制限を最小限に抑えつつ、Javaアプリケーションの起動とウォームアップを改善することを目的としています。これは、トレーニング実行中にアプリケーションの動作を記録し、それをAhead-of-Timeキャッシュに保存して、その後の実行に活用することで実現されます。
Project Leyden
https://openjdk.org/projects/leyden/
JEP 483を通じてJDK 24で導入されたAOTキャッシュは、JEP 515によってJDK 25で拡張され、トレーニング実行中にメソッドプロファイルを収集できるようになりました。これにより、JVMはプロファイルの収集を待つ必要がなく、アプリケーションの起動直後に最適化されたネイティブコードを生成できるようになります。その結果、ウォームアップ時間が短縮されます。
JEP 483: Ahead-of-Time Class Loading & Linking
https://openjdk.org/jeps/483
JEP 515: Ahead-of-Time Method Profiling
https://openjdk.org/jeps/515
この機能により、同様のトレーニングを施したアプリケーションを実行する場合、JDK 24と比較して一部のサンプルプログラムの起動が15~25%高速化しています。
この機能強化と、JDK 25で提供されたJEP 514により、Project Leydenは順調に進展しています。
JEP 514: Ahead-of-Time Command-Line Ergonomics
https://openjdk.org/jeps/514
JEP 519: Compact Object Headers
コンパクトオブジェクトヘッダーは、JDK 24で実験的機能として追加されましたが、現在は製品機能として正式に採用されました。
-XX:+UseCompactObjectHeadersで有効にすると、ヒープ上のすべてのオブジェクトのサイズが、通常4バイト縮小します。これにより、ヒープ容量が大幅に節約され、キャッシュの局所性が向上し、GCの活動が減少するため、多くのベンチマークや実環境のアプリケーションにおいて、大幅な速度向上が確認されています。
ユーザーの皆様には、ぜひこの機能を試していただき、フィードバックをお寄せいただくことを強くお勧めします。今後のリリースでは、これをデフォルトで有効にすることを検討しています。
Various Interpreter Improvements
- [JDK-8356946] x86: Optimize interpreter profile updates – Java Bug System
https://bugs.openjdk.org/browse/JDK-8356946 - [JDK-8357223] AArch64: Optimize interpreter profile updates – Java Bug System
https://bugs.openjdk.org/browse/JDK-8357223 - [JDK-8357434] x86: Simplify Interpreter::profile_taken_branch – Java Bug System
https://bugs.openjdk.org/browse/JDK-8357434
これらの改善点により、インタプリタによるプロファイルカウンタの更新処理が大幅に強化されました。起動時およびウォームアップ中に、バイトコードインタプリタはどのメソッドや分岐が使用されているかをプロファイリングし、その情報を基にJVMは何をどのようにコンパイルすべきかを判断します。これらのカウンタを更新する処理は、アプリケーションの起動時やウォームアップ中に顕著に感じられることがあります。
個々の最適化だけでは目立たないこともありますが、リリース全体で見れば、その効果は確実に積み重なっていきます。JDK 24から25への移行に伴い、単純な「Hello World!」を実行する時間は、JDK 25において約28.7msから約25.5msへと短縮されました。導入直後から実に12%の高速化が実現しています。
Project Leydenのユーザーは、大規模な環境においてさらなるパフォーマンス向上を実現できるかもしれませんが、追加コストなしで測定可能な改善が見られることは素晴らしいことだと考えています。
Other Runtime Performance Enhancements and Bug Fixes
- [JDK-8355646] Optimize ObjectMonitor::exit
この同期処理の改善により、ロックを解放して再取得せずに、待機中のスレッドを直ちに解放できるようになりました。これにより、競合が比較的少ない一部のロックにおけるレイテンシが低減されます。 - [JDK-8348402] PerfDataManager stalls shutdown for 1ms
JVM シャットダウン時の短いスリープを排除することなどが挙げられます。短時間で実行されるコマンドラインツールやビルドシステムなどにとって有益です。 - [JDK-8241678] Remove PerfData sampling via StatSampler
定期的に実行されるタスクを削除する、クリーンアップのしくみ。 - [JDK-8353273] Reduce number of oop map entries in instances
- [JDK-8354560] Exponentially delay subsequent native thread creation in case of EAGAIN
- [JDK-8352075] Perf regression accessing fields
フィールドが多いクラスにおいて、インタープリタの速度が大幅に低下する可能性があったJDK 21からの問題を修正しました。
That’s All, Folks!
JDK 25はすでに一般公開されていますので、ぜひお試しください。JDK 25とJDK 21のパフォーマンスを比較したい場合は、Devoxx Belgium 2025で発表されたセッション「From JDK 21 to JDK 25 – Java Performance Update 2025」もおすすめです。
From JDK 21 to JDK 25 – Java Performance Update 2025
https://inside.java/2025/10/18/devoxxbelgium-java-performance-update/
アプリケーションのテストや移行を行う際は、現在のJDKと比較して、JDK 25でのパフォーマンスを測定してみてください。パフォーマンスの低下など、何か気になる点はありましたか?ぜひコミュニティに参加して、私たちにお知らせください!関連するメーリングリストに参加し、問題点を報告してください。
Mailing List Index
https://mail.openjdk.org/mail/lists/
私たちはすでに、次期リリースとなるJDK 26に向けた充実した改善点を検討しており、2026年春にはそれらについて詳しくご紹介できることを楽しみにしています。それでは!
