原文はこちら。
The original article was written by the following co-authors.
JONAS NORLINDER (Uppsala University, Sweden)
ERIK ÖSTERLUND (Oracle, Sweden)
DAVID BLACK-SCHAFFER (Uppsala University, Sweden)
TOBIAS WRIGSTAD (Uppsala University, Sweden)
https://dl.acm.org/doi/epdf/10.1145/3689791
Abstract
移動ガベージコレクタ[Moving garbage collectors (GCs)]では通常、メモリ解放のために有効(生存)オブジェクトを退避し、連続したメモリ領域を再利用しようとします。退避(evacuation)の実行は通常、トレース中(scavenging、掃き集め)もしくはトレース後有効オブジェクトの識別が完了した時点(mark–evacuate)です。scavengingでは通常、より多くのメモリ(移動対象のすべてのオブジェクトのメモリ)を必要としますが、密度の低いメモリ領域では作業量が少なくなります(シングルパス)。このため、youngオブジェクトの収集に適しています。mark–evacuateの場合、密度の低い領域周辺への再配置に注力することにより、通常はそれほどメモリを必要とせず、オブジェクトの密集した(密度が高い)メモリ領域では作業量も小さくなります。そのため、oldオブジェクトの収集に適しています。またmark–evacuateは、有効オブジェクトの識別をより高速に完了させるため、有効オブジェクトの識別が完了した直後に(退避が完了したときではなく)メモリを再利用できるconcurrent GCに適しています。ただし、youngオブジェクトについてはscavengingよりも多くの作業が必要です。そこで、youngオブジェクトに対して、mark–evacuateの利点とscavengingの利点を組み合わせたconcurrent GCのための代替アプローチを提案します。
このアプローチは、concurrent GCがyoungオブジェクトを再配置するまでに、それらのオブジェクトはすでに到達不能になっている可能性が高いという観察に基づいています。再配置の遅延により、mark–evacuateのデフラグメンテーションフェーズにおける再配置のほとんどを通常は排除できます。 今回提案しているアプローチでは、scavengingのようにトレース中にオブジェクトを再配置します。ただし、現在のGCサイクルで有効な全オブジェクトを再配置するのではなく、前のGCサイクルから生き残った、実際に有効である密度の低いオブジェクトクラスタを遅延して再配置します。これにより、GC終了までにメモリ不足に陥るのを回避するための、通常は「無駄」になるconcurrent GCのメモリの余裕が、GC作業の大部分を占める再配置作業の大部分を排除するために使用される資産へと転換されます。この手法をmark-scavengingと呼び、MS-ZGCというコレクターとしてOpenJDKのZGCの上に実装した上で、MS-ZGCとZGCを比較するパフォーマンス評価を行いました。最も顕著な結果は、無効オブジェクトの再配置が最大91%削減されたことです(マシン依存の要因によって変わります)。
| CCS Concepts | Additional Key Words and Phrases |
|---|---|
| Software and its engineering → Garbage collection | concurrent, garbage collection, mark-evacuate, scavenging |
ACM Reference Format:
Jonas Norlinder, Erik Österlund, David Black-Schaffer, and Tobias Wrigstad. 2024. Mark–Scavenge: Waitingfor Trash to Take Itself Out. Proc. ACM Program. Lang. 8, OOPSLA2, Article 351 (October 2024), 28 pages.
https://doi.org/10.1145/36897911
1 Introduction
メモリ管理はソフトウェア開発において重要な要素です。自動メモリ管理、または「ガベージコレクション」(GC)は、現代の言語ランタイムがメモリ安全性やタイムリーなメモリ回収などを確保する上で主流の方法です。GCは、無効なポインタやメモリ解放後の利用といったバグの発生を完全に回避するだけでなく、ライブラリのコンポーネント化も保証します。というのも、オブジェクト所有権の維持に関する特定の戦略に縛られずに記述できるためです。
ガベージコレクタのスタイルが異なれば、メモリを安全に再利用する、つまり、有効オブジェクトが決して収集されないようにするために使う手段も異なります。”GC handbook”では、オブジェクトが有効かどうかを次のように定義しています。
「将来のミューテーター実行時にアクセスされる場合、オブジェクトは有効である」(ミューテーター(mutator)とは、GCの観点から見たプログラムスレッドのビューです)
参照カウントアルゴリズムは、オブジェクトへの参照ポインタの数を追跡し、ゼロ以外の個数であれば有効とみなします。カウントは概算や繰り延べされる場合があり、オブジェクトの参照カウントがゼロにならずにガベージになるサイクルを処理するために、GCの追跡機能と組み合わされることも多々あります。
追跡型コレクター(tracing collectors)は、有効性を到達可能性として暗黙的に定義しています。例えば、OpenJDKのSerial GCとParallel GCは、GC実行中(STW、stop-the-world、一時停止)はプログラムを一時停止します。コピーコレクター(copying collectors)であるSerial GCとParallel GCは、ルートセットからオブジェクト・グラフを走査し、到達可能なすべてのオブジェクトを再配置して、それらのオブジェクトが占めていたスペースを再利用できるようにします。これは、GCの文献ではscavenging(掃き集め)と呼ばれる手法です。プログラムが一時停止するタイミングは、収集できるガベージの量に影響を与える可能性があります。GC開始直前に、何らかの操作によってオブジェクトが到達不能になった場合、そのオブジェクトは再利用されます。そうでない場合、上記の意味では有効ではないものの、GCが再実行されるまでは、そのオブジェクトはスペースを占有し続けます。
ほぼ並列実行する追跡型コレクター(mostly-concurrent tracing collectors)の場合、メモリ内のscavengingや分割トレースを使って、有効性を判断したり、有効オブジェクトのメモリ内の新しい領域へのコピーを個別の操作(マーキングと再配置)として実行したりします。このテクニックはmark–evacuateと呼ばれます。この手法を採用する理由のひとつは、プログラムを中断せずにマーキングを行うのは比較的容易ですが、再配置はそうではないからです。OpenJDKのG1は、youngオブジェクトに対してはscavengingを、oldオブジェクトに対してはmark–evacuateを使用します。C4、Shenandoah、ZGCのようなほぼ完全に並列処理可能なコレクター(almost fully-concurrent collectors)は、(少なくとも通常の動作条件下では)オブジェクトの再配置のためにプログラムを停止させることはありません。 並列処理可能なコレクターでは、オブジェクトの有効状況はより複雑になります。なぜなら、scavengingもしくはmarkingフェーズ中もしくはその前後でオブジェクトが到達不能になる可能性があるためです。一方、STW コレクションでは、到達不能になるのは完全なコレクションの前後です。GCサイクルの開始後に到達不能になったオブジェクトは、次のGCサイクルまで回収されないため、floating garbage(浮遊ガベージ)と呼ばれます。
SPECjbb2015とDaCapoベンチマークスイート(§2.4参照)におけるSerial、G1、ZGCコレクターの再配置効率を調査したところ、再配置作業の大部分が、すでに破棄オブジェクト、floating garbage、または間もなくガベージになるオブジェクトに費やされていることが分かりました。平均すると、GCサイクル𝑘で再配置された全バイト数の55%(Serial)、69%(G1)、64%(ZGC)が、サイクル𝑘+1のマークフェーズでは到達不能でした。これは、多くのプログラムが、つまりほとんどのオブジェクトはyoung世代で破棄されるという弱世代仮説を満たしていることを考えると、さほど驚くことではありません。しかし、ZGCの結果をさらに詳しく調べたところ、再配置されたバイト数の平均63%は、移動された時点で既に無効状態であることが分かりました。言い換えれば、全体の63%のケースでは、マーキング中に決定された「到達可能性としての有効性(liveness-as-reachability)」が、マーキング終了までに「将来アクセスされるものとしての有効性(liveness-as-future-access)」に対応しなくなります。具体的には、平均して全再配置バイト数の63%がメモリを解放する機会を逃し、その代わりにコピーによるCPUオーバーヘッド、メモリバスのトラフィック増加、ZGCがオブジェクトが存在する領域の退避を決定するまで(実際には退避しない可能性もある)オブジェクトが領域を占有することにつながっていることを意味します。
ZGCの場合、GCに関する文献から直感的に導かれる解決策は、マーキングと再配置間の時間短縮でしょう(ZGCが対象とするTBサイズのヒープでは、この時間は数秒になる可能性があり、その結果、古くなった有効情報につながる可能性が高い)。本論文では、その代わりに、再配置を可能な限り遅らせるという逆のアプローチを探ります。我々のインサイトは、オブジェクトの「減衰」(decay)が速いことを考えると、このような遅延はオブジェクトが無効になる確率を高め、それによってオブジェクトを移動する必要性を全くなくすというものです。このため、(オブジェクトの少ない)領域が占有するメモリを緊急に必要とするタイミングまで、あるいは、有効性の再計算の一環として、次のGCサイクルまで再配置作業を遅らせます。scavengingと離散的なマーキングと評価の設計要素を組み合わせることにより、再配置を遅延させ、サイクル内のオブジェクトの無効率を活用できます。それがmark-scavengeという、両アプローチの長所を併せ持つアルゴリズムです。今回、世代別ZGC上にプロトタイプを実装し、我々の設計を評価しました。評価の結果、我々の設計は(young世代において)無効オブジェクトの再配置を大幅に減少させることがわかりました。上記の実験では、無効オブジェクトの再配置が63%から4%に減少しました。別のマシンでは40%の削減が見られました。
本論文では以下の内容を発表します。
| 1 | 「無駄な再配置作業」、すなわち、Serial、G1、ZGCにおいて、退避させられたオブジェクトがどの程度無効になっているか、あるいはほぼ無効であるかの調査を行う(§2.4)。 |
| 2 | mark–scavengeという、古典的なmark-evacuateとscavengingを組み合わせた手法を提案する。これは退避を遅らせると同時に、両者の補完的な長所を兼ね備えるものである。退避までの時間を遅らせることで、オブジェクトが到達不可能になる確率を増加させ、退避のコストを削減する(§3)。 |
| 3 | 世代別ZGC(§4)に我々の提案を実装する。 |
| 4 | 我々の設計を最新のベンチマークで評価する(§5)。評価の結果、mark-scavengeは無駄な再配置作業を大幅に削減することがわかった。これはGCサイクルの短縮につながり、GCによるメモリの回収速度が向上する。システムに十分な余裕(メモリの余裕)があり、GCがパフォーマンスのクリティカルパスにならない場合、この削減はパフォーマンスに影響を与えない。しかし(メモリの)余裕が少ない場合、プラスの効果が現れ、マシンがオーバーサチュレートし、GCとミューテーターがリソースを競合する場合、すべてのヒープサイズで明確な改善が見られる。 |
2 Background: Scavenging and Mark–Evacuate
§3でmark–scavengeアルゴリズムを説明する前に、scavengingとmark–evacuateという、このアルゴリズムの基になる2個のアルゴリズムについて説明します。Table 1には両アルゴリズムの概要をまとめています。
| Scavenging | Mark–Evacuate | |
|---|---|---|
| 退避時のワークセットサイズ | 不明 | 既知 |
| 発見から再配置までの時間 | 即時 | 遅延 |
| 退避の順序 | Graph | アドレス |
| OOM フォールバック | Pin | インプレース圧縮(free-list) |
| 退避の検出 | 遅延 | 即時 |
| トラバーサルの回数 | 1 | 1-2 |
McCarthyは1960年に古典的なmark-and-sweepアルゴリズムを導入しました。sweepは、到達不可能なオブジェクトをすべて「解放」することでメモリを回収します。sweepをオブジェクトの断片化解消に置き換えることで、無効なオブジェクトを解放する代わりに、有効オブジェクトを再配置することで、メモリの効率性が高まり、通常はより高速になります。少なくとも、オブジェクトの無効化率が一般的に非常に高いyoungコレクションでは、この方法が有効です。文献では、このアプローチは、mark-evacuate(マークと退避)と呼ばれています。退避により、ページ上のすべてのオブジェクトを再配置して、そのページを再利用できるようになります。オブジェクトの再配置が、有効オブジェクトを新しい領域にコピーすることで行われる場合、マークと退避のステップを1つにまとめることができます。このアプローチをscavenging(掃き集め)と呼び、ヒープ走査中にオブジェクトを発見した場合、マークする代わりにオブジェクトをコピーします。Fig. 1aとFig. 1bでは、具体的なシナリオを用いて、scavengingとmark–evacuateを視覚的に説明しています。§3でのmark–scavengeの説明の一部として、3個のアルゴリズムすべてに関する高レベルの説明をFig. 4に記載しました。より詳細な内容に関心のある読者向けに、このセクションでは先んじてFig. 4a およびFig. 4b の参照をお知らせします。初回の読み取りの際には、これらの図はスキップしていただいて結構です。
Fig. 1a(scavenging)では、オブジェクト𝑎から𝑓を検出し、from-space領域𝑝1と𝑝2からto-space領域𝑝3と𝑝4に、グラフ順(𝑎、𝑏、𝑑、𝑓、𝑒、𝑐)に再配置します。最終的には、𝑝4は使用されませんが、発見されたすべてのオブジェクトを必要に応じて遅滞なく再配置できるようにするために、確保しておく必要がありました。(破線の四角で示すように)𝑡5の後、𝑝2は完全に退避されます。しかし、このアルゴリズムでは、𝑝1と𝑝2の両方が解放される𝑡7まで、𝑝2が完全に退避されたことを確実に知ることはできません。

(a) Scavenging 各行(𝑡1~𝑡7)は、scavenging中の1つの時間ステップを示している。𝑝1と𝑝2は、from-space内の領域、𝑝3と𝑝4は、to-space内の領域。青色のオブジェクトは、from-space内で発見されたもので、白色のオブジェクトは発見されていない。緑色のオブジェクトは、青色のオブジェクトのコピーを再配置したもの。灰色のオブジェクトは、ガベージ。

(b) Mark–Evacuate 時間ステップ𝑡1~𝑡6はマーキングに、時間ステップ𝑡7~𝑡10はデフラグメンテーションに対応する。𝑝1と𝑝2はfrom-space内の領域、 𝑝3はto-space内の領域。白いオブジェクトが到達可能で、青はマーク済み。緑は黄色のオブジェクトのコピーを再配置したもので、灰色はガベージ。
Fig. 1. Explaining the differences between scavenging and mark–evacuate using a specific scenario.
Fig. 1b(mark–evacuate)では、オブジェクトa~fがグラフ順(𝑎、𝑏、𝑑、𝑓、𝑒、𝑐)に発見、マークされ、その後アドレス順(𝑎~𝑓)で再配置されます。マーク処理後に退避に必要な領域が計算されるため、to-spaceの1個の領域𝑝3のみが割り当てられることに注目してください。ただし、離散時間ステップの数は、scavenging処理に関連して7から10に増加します(「チート」として、1つの時間ステップで領域全体の退避を行う場合でもです)。
scavengingとmark–evacuateの両方の実装は、マネージド言語では一般的なものであり、単一システムで両方のアプローチを組み合わせることも一般的です。例えばOpenJDKの場合、G1、Parallel、Serialのすべてがyoungヒープでscavengingを使用し、oldヒープではmark–evacuateを使います。対照的に、世代別ZGCや世代別Shenandoahではyoung/oldヒープの両方でmark–evacuateを使います。
2.1 Pros and Cons of Scavenging
オブジェクト検出後ただちに再配置することの利点(Fig. 4aの7行目から9行目)の一つとして、1回のみのヒープスキャンゆえに、GCサイクルの実行時間が短縮される点があります(これはFig. 4aのサイクルロジックで確認できます)。scavengingの欠点は、GCサイクルの開始時に利用できる、事前有効情報がないことです。有効オブジェクトの数がわからないため、前回のGCサイクル以降に割り当てられたメモリをできるだけ多く確保して、退避中にコピーしたオブジェクトを保持する必要があります。その結果、scavengingを使用すると、GCサイクルが終了するまで、つまり退避されたページが解放され、scavenging用に保守的に確保された未使用のメモリが返却されるまで、100%のメモリオーバーヘッドが発生します(Fig. 1aの𝑝4で示されている通りです)。
さらに、ヒープが単一の連続領域であるか、複数の領域に分かれているかに関わらず、最後の有効オブジェクトが領域からコピーされ、その領域が事実上空き領域となったことを、scavengingでは知ることができません。したがって、scavengingで解放されたメモリは、作業セット全体を走査した後で初めて利用可能になります。Fig. 1aでは、𝑝2が𝑡5で退避されたものの、𝑡7まで解放されないことがわかります(Fig. 4aの28行目)。
2.2 Pros and Cons of Mark–Evacuate
mark–evacuateのマークフェーズだけであれば、再配置を一切行わないため(Fig. 4bの31行目から35行目)、scavengingよりも高速です。マークが完了した直後(53行目)に空のページをすぐに再利用でき、STW GCのようにmark–evacuate GCサイクル全体が完了するのを待つ必要がないため、これはconcurrent GCにとってメリットがあります。並行処理環境では、サイクルが長くなるほど、GCサイクル中に、ミューテーターによる並行割り当てによりメモリ不足に陥るリスクが高くなります。並行処理環境では、mark–evacuateでは、concurrent GCのために回収されたメモリを使用できるまでの時間が短いのですが、STW GCでは逆に長くなります。 ヒープを最悪の場合2回巡回する代償として、それぞれのマーク(Fig. 1bの𝑡1–𝑡6)と退避(𝑡7–𝑡10)のフェーズを設けることで、scavenging時に存在するすべての有効オブジェクトを退避させるのに必要なメモリの量がわからないという問題に対処しています。Fig. 1bでは、各リージョンの有効バイト数は𝑡6の終了時にわかります(したがって、必要なのは𝑝3だけです。)
メモリを連続したメモリの離散的な領域に分割するコレクタでは、liveness information(有効性情報)を収集し、オブジェクトの密度の低い領域のみを退避させることで、退避の投資対効果をさらに最適化できます(Fig. 4bの54行目で何ページが退避用に選択されているかによって決定される)。これにより、メモリとCPUのオーバーヘッドが削減され、マーキング後のセカンドパスのコストが軽減されます。極端な例として、オブジェクトで完全に占有された領域を退避させると、メモリの再利用が行われなくなりますが、有効性情報があれば、このような状況は簡単に回避できます。有効性情報があれば、オブジェクトグラフの順序ではなく、アドレス順序で退避を進めることができます(Fig. 4bの42行目)。これは再配置されたオブジェクトのアドレス順を保持しているためで、再配置中に(オブジェクト密度の大小に応じて)プリフェッチしやすくできます。領域ベースのコレクタでは、領域がいつ退避されたかを検出するのは簡単で(Fig. 4bの52行目)、退避中にそのメモリをシステムに戻し、同じサイクル中の他の領域の割り当てや退避に再利用できます。Fig. 1bでは、𝑡8の終了直後に解放されています。
mark-evacuateの具体的な実装例として、ZGCコレクタを考えてみましょう。マーク中にヒープ全体の有効性情報を収集した後、メモリ内のすべてのページ(ZGCでは領域を指す)を有効バイト数の多い順にソートしたリストを作成します。続いてZGCは、結果として得られるヒープの断片化の合計がユーザー定義の閾値を超えないように、最もまばらページを退避用に選択します(図4bの54行目)。これにより、最小限のバイト数で最大限のメモリを解放します。
concurrent GCにおける 2 段階アプローチの欠点は、退避を促すマーキング中に収集された有効性情報が、実行時に古くなっている可能性があることです(Fig. 1b において、オブジェクト𝑎は𝑡1では有効とマークされていたが、その有効性情報は、𝑡7におけるオブジェクト𝑎の到達可能性に関係なく、𝑡7まで適用されません)。有効であるとマークされたオブジェクトがその後無効化したり到達不能になったりする確率は、有効であるとマークフェーズの長さに比例して増加します。§2.4で、これが退避中に厳密には不要なオブジェクトのコピーを生成することにつながることを見ていきます(これらのすべてのGCは世代別GCです。これらのGCは通常はマーク時間を短くして、有効性情報を新鮮に保つべきであることに注意してください)。
2.3 Relocation Failure Options
scavengingでは事前の有効性情報を持たないため、オブジェクトの再配置に必要な割り当てに失敗した場合の選択肢は限られています(これは、例えば必要なメモリオーバーヘッドの予測ミスや、コンカレント・コレクタの場合には突発的な割り当ての急増が原因で発生する可能性があります)。再配置に必要なメモリを割り当てられないスレッドをrelocation stall(再配置の停止)と呼びますが、これは再配置を実行するスレッドが通常、より多くのメモリを利用可能になるまでブロックしなければならないからです。relocation stallを解決するための代替策のひとつは、退避を中止してオブジェクトをそのままにしておくことです。これは再配置の停止を解決しますが、(退避を行うコレクターでは)メモリの空きにつながることはありません。世代別GCでscavengingを使用している場合、(より多くのメモリを解放することを期待して)メジャーコレクションを実行するという選択肢もあります。G1は両方を組み合わせて使用します。まずピンニングを使用し、回収されたメモリが少なすぎる場合には、その後でメジャー・コレクションのトリガーを使用します。
有効性情報が利用可能な場合、さらに2つのアプローチが可能です。すなわち、その領域をその場所で整理(インプレース圧縮)し、残りのメモリを利用可能にするか、有効性情報を使用して有効オブジェクト間の「穴」に割り当てるかです。ZGCはbump-pointer割り当てのみをサポートしており、インプレース圧縮を使用します。インプレース圧縮中のページ上のオブジェクトにアクセスしようとする変更スレッドは、該当のオブジェクトが再配置されるまでブロックしなければならないため、これはZGCにとって最悪のケースです。
2.4 Wasted Work and Floating Garbage
コンカレント環境では、scavengingとmark–evacuateのどちらもfloating garbage(GCアルゴリズムが知らないうちにGCサイクル間にガベージになるオブジェクト)に悩まされます。コピー・コレクタでfloating garbageを検出できない場合、実質的に空いているメモリをシステムに返すことができないだけでなく、ガベージ・オブジェクトを再配置することによってリソースを浪費してしまいます。
冒頭で例証したように、これはミューテータがGCが検出しない方法(オブジェクト・グラフの残りの部分から切り離す)でサブグラフの有効性を同時に変更する場合に発生する可能性があります。マーキング・アルゴリズムによっては、切断されたサブグラフは、現在のGCサイクルの間、有効とみなされる可能性があります。例えば、G1とZGCは共に、snapshot-at-the-beginning markingを使用します。これは、write barrierが、マーキング中にオブジェクトグラフへの同時変更を検出し、マーキング開始時に到達可能なすべてのオブジェクトが有効であるとマークされることを保証します。
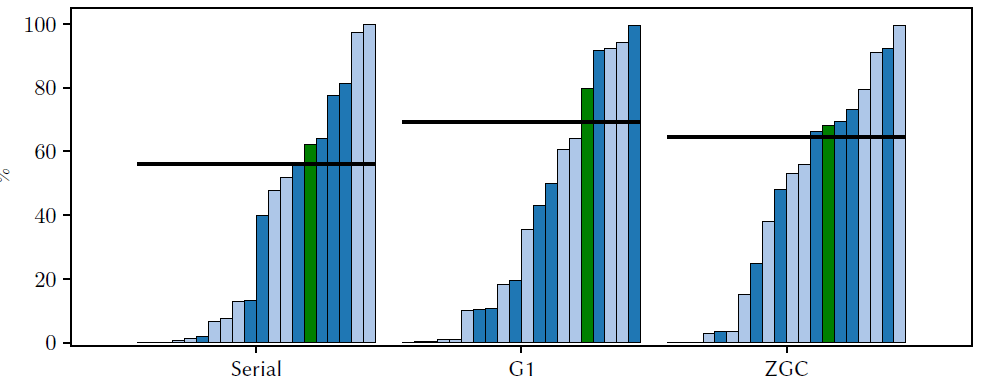
Fig. 2は、シリアル(STW)、G1(ほぼ同時)、およびZGC(ほぼ完全同時)のGCにおいて、再配置された全オブジェクトのうち、後続のマークフェーズで到達不可能と判断されたオブジェクトの割合を測定した実験結果です。ZGCについては、ZGCのload barrierロジックにフックすることにより、再配置されたオブジェクトのうち、再配置の時点で無効であった(ミューテーターによって二度とアクセスされなかった)オブジェクトの割合も測定しました。より厳密な結果をFig. 3に示し、比較しやすいようにFig. 2のZGCの結果も併せて示します。
Fig. 2中の棒グラフの各棒は1つのベンチマーク結果を表しています。棒は昇順にソート、GCごとにグループ化済みです。すべてのベンチマークの傾向に関心があるため、プロットでは名前を省略して可読性を上げています。スループットのベンチマークとレイテンシのベンチマークは、後者を濃青色表して区別しています。SPECjbb2015と DaCapo 23.11-chopinベンチマークスイートを使用し、広範な様々なワークロードをカバーしました。
Note that Fig. 2では、サイクル𝑘で到達可能なオブジェクトがサイクル𝑘+1で到達不可能になったもの(再配置時にすでに到達不可能だったものではありません)を示していることに注意してください。しかし、ZGCでのload barrierベースの測定による結果がFig. 3で示すように、再配置されたオブジェクトの大部分は(少なくともZGCでは)すでに無効状態(到達不可能かどうか)です。悲しいかな、オブジェクトを再配置すべきか、無効のまま残すかを問うことができるoracle(神託)は存在しません。

これらの結果を考える1つの方法は、再配置するかどうかの決定を次のサイクルのマーキングまで遅らせることができれば、回避できる再配置の割合を示しているということです。平均して全再配置バイト数の60%以上が “left for dead”(無効のまま放置)されている可能性があります。
ヒープのサイズ、livesetのサイズ、コア数、割り当て率など、この数字に影響を与える要因はたくさんあります。とはいえ、弱世代仮説を満たすプログラムでは、再配置を遅らせることができるアルゴリズムは、かなりの再配置作業を回避し、結果としてメモリとCPUの両方を節約できます。
このため次節では、再配置を遅延させ、無駄な作業を回避するために、mark–evacuateとscavengingの両方の要素を組み合わせたmark–scavengeをご紹介します。
3 Mark–Scavenge
この研究の基礎に流れる洞察は、scavenging(即座に再配置するが、より高いメモリーオーバーヘッドという負担がある)とmark–evacuate(より低いメモリーオーバーヘッドではあるが、より多くの作業と古い有効性情報との作業という負担がある)の相補的な性質、そして、これらの設計上の決定が無駄な再配置作業に与える影響です。 私たちは、両方のアプローチを組み合わせた”mark–scavenge”を提案します。これは、両方の長所を最大限に活かしつつ、無駄な再配置作業を削減します。
一般的に、コンカレント・コレクターのメモリ回収率は STW コレクターよりも低いため、前者はより大きなメモリの余裕領域を必要とします。 この余裕領域は、コンカレント GC のコストとして見なされることが多いですが、私たちはこれを、GCの作業を遅らせるという事実を隠すことを可能にする資産に変えます。
Table 1のハイライト部分は、mark–scavengeがscavengingとmark–evacuateの特徴を良いとこ取り(cherry-pick)していることを示しています。
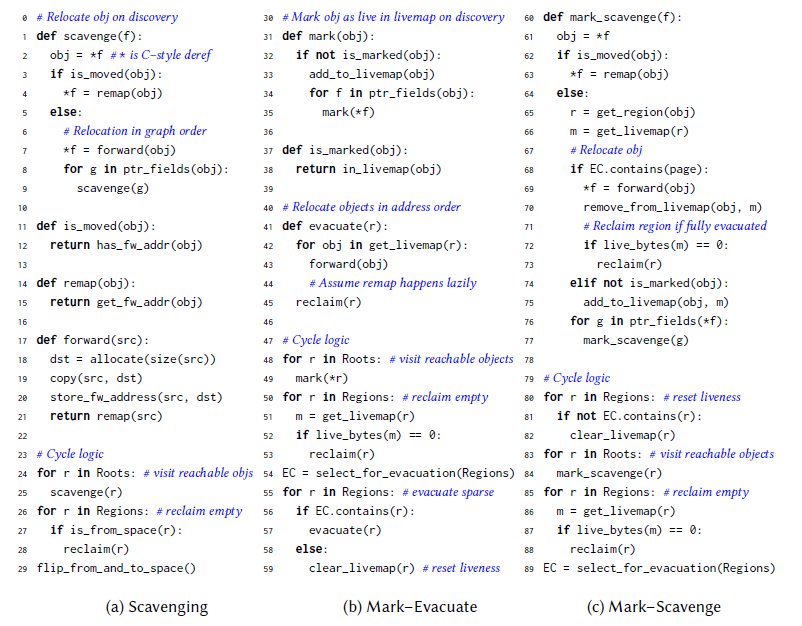
Fig. 4は、左から右に向かって、scavenging、mark–evacuate、mark–scavenge(このセクションで説明します)をハイレベルで示しています。「サイクルロジック」の下のコードは、各アルゴリズムがGCサイクルごとに実行する動きを示しています。
mark–scavengeサイクルは80行目から始まります。青字のコメントは、このセクションおよび前セクションで指摘したプロパティとコードの関係を大まかに示しています。mark–evacuateのコードはscavengingのコードの関数を再利用し、mark–scavengeのコードは両方の関数を再利用します。簡潔にするため、自明な名前を持つはずの単純なヘルパー関数の定義は省略します。Roots、Regions、およびECはグローバルリスト変数です。ECは退避のために選択されたRegionsのサブセットです。関数 scavenge()とmark_scavenge()はどちらも、変数またはフィールドへのポインタを引数にとり、転送(その変数またはフィールドが指すオブジェクトのコピー)または再マッピング(すでにコピーされたオブジェクトへのポインタを新しい場所に更新)の一環として引数を更新します。簡単にするために、割り当て(18行目)は常に成功すると仮定します。この単純化については、Fig. 5で再検討します。
3.1 Selective Relocation
Mark–scavengeはimmixに似ており、有効性情報(75行目)の収集と再配置(69行目)の両方の目的を果たすために、単一のヒープ走査を使用します。再配置は選択的(68行目)であり、前のGCサイクルからの有効性情報(89行目)に基づいて選択を実施します。詳細はselect_for_evacuation()にカプセル化されています。
この関数は、有効性情報を使い、退避先として最も密度の低い領域を選択し、投資収益率の低い、密度の高い領域はそのままにします。これにより、これらの領域上のオブジェクトは、その後のアクセス時、またはその後のGCサイクルのヒープ走査時に再配置されます。再配置がグラフ順に行われるにもかかわらず、有効性情報により、領域が完全に退避されたことを即座に検出できます(72行目)。
退避対象として選択されなかった領域や、以前の有効性情報を持たない(つまり、新しく割り当てられたオブジェクトのみを含む)領域では、マーキングのみを行い、決して再配置は行いません。以上の結果、オブジェクトは2回のGCサイクルを生き延びた後に、最も早いタイミングで再配置されることになります。オブジェクトの再配置タイミングを遅らせることは、弱世代仮説に則ったものであり、次の2つの目的を果たします。
- オブジェクトが再配置される前に無効化する確率が高まるため、再配置の圧力が減り、無駄な再配置作業が減少する
- 生存(survival)がさらなる生存の予測因子であることを踏まえると、最終的なオブジェクトの再配置により無駄な再配置作業につながるリスクは減少する
本論文のタイトル “waiting for trash to take itself out”(ガベージが自ら出て行くのを待つ)は、上記に由来しています。GCを遅らせる理由は、単に無駄なGC作業を回避するためだけではなく、オブジェクトを無効化する時間をより長く確保し、オブジェクトを移動する必要性を完全に排除するためです。
再配置とメモリ回収の関連性により、オブジェクトがGCに参加するまでの時間を遅らせると、システム上のメモリ圧迫が増加する可能性があります。 それでは、その緩和方法について説明します。
3.2 The Tension Between Immediate Evacuation and Wasted Relocation Work
アドレス順に従った退避により、最小限の時間で領域が利用可能になります。 scavenging方式の再配置はグラフ順に進行するため、mark-evacuate方式よりも時間がかかります。 しかし、前サイクルの有効性情報により、領域内の最後のオブジェクトが再配置されたことを即座に検出できます(72行目)。遅い退避とallocation-pressure(割り当て圧力)が組み合わさってmemory pressure(メモリ圧力)が危険なほど停滞しそうな場合、「フォールバック」してアドレス順に領域を退避します。例えば、18行目で呼び出された割り当て関数が失敗した場合、有効性情報を持つ任意の領域を選択して退避するか、インプレース圧縮で割り当てを実現します。領域を退避するには、退避先の利用可能なメモリが必要です。これは、退避用に初期スペースを確保し、退避用に確保したスペースの一部を「追加」してバッファを拡張し、追加の退避を可能にすることで対処できます。初期スペースを確保する代わりに、リージョンに対してインプレース圧縮を実行し、その上で退避を継続することもできます。Fig. 5aは、この疑似コードを示しています。ここで、Bufferはメモリ確保領域です(102行目、113行目)。ここでは、説明を簡単にするために、メモリ予備領域の「上積み」は不要であると仮定します。 また、色を使って列をまたぐインデントを読みやすくしています。

_tlab is a thread-local allocation buffer (a region that fast-path allocations go into).(mark–scavenge(左と中央)とミューテーター再配置(右)における割り当てエラーの処理。変数_tlabはスレッドローカルな割り当てバッファ(高速パス割り当てが格納される領域)。)退避やリージョン圧縮に使われる有効性情報では、控えめではありつつも多めに見積もるのが一般的です。したがって、以下で詳しく説明するように、メモリを高速に利用可能にするためのコストは、デッド・オブジェクトの再配置のリスクが高まることを意味します。
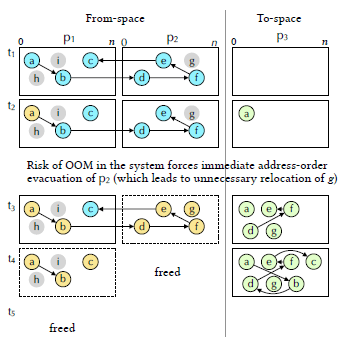
Fig. 6は、Fig. 1a、Fig. 1bと同じ初期ヒープを示しています。この例では、領域𝑝1と𝑝2が退避対象として選択されており、GCワーカーがオブジェクトを発見すると、それらのオブジェクトを𝑝3に移動させます。𝑡2で、オブジェクトaが𝑝3に移動されます。同時にシステムはOOMに近づいているため、mark–scavengeアルゴリズムが即時退避のために空きの多い領域を選択します。この例では𝑝2です。
𝑝2を迅速に退避するために、𝑝2の有効性マップをアドレス順にたどり、𝑑、𝑒、𝑔、𝑓を(この順番で)𝑝3にコピーします。注目すべきは、𝑔はfloating garbage(マークはされているがオブジェクトグラフから到達できない)である点です。したがって、𝑔の再配置は無駄な作業です。
Shenandoah、ZGC、C4のようなコンカレント・コレクターは、ミューテーターがオブジェクトを再配置できるようにして、遅延を最小限に抑えようとします。ミューテーターが退避対象のリージョン上のオブジェクトにアクセスする場合、アクセスを開始する前に再配置が実行されます。GCワーカーでミューテーターがブロックされるのを回避するだけでなく、GCの負荷も軽減でき、再配置のコストを(潜在的に)はるかに多いスレッド数で分散できます。アクセス直前に再配置を実行するミューテーターは、再配置時にオブジェクトが有効だったことを示します。
Fig. 5bは、ミューテーター駆動の再配置で、リージョンが退避されたことを検知し、その領域を再利用する方法を示しています。ロード値バリアは、y = x.fがy = loaded_value_barrier(&x.f)としてコンパイルするように、ヒープからのポインタロードをトラップします。
3.3 Cost of a GC Cycle
3個のアルゴリズムはいずれも、livesetのサイズに対して線形です。scavengingの場合、有効オブジェクトを1回だけ走査し、発見の都度再配置します。livesetのサイズを𝑛で表すとすれば、時間計算量は𝑂(𝑛)と表現できます。mark–evacuateの場合、ヒープを2回走査します。2回目の再配置のパスでは、最悪の場合、すべてのオブジェクトを再配置します。したがって、時間計算量は𝑂(2·𝑁)です。mark– scavengeの場合、1回の走査ですが、発見の都度マークし、再配置を遅らせてもオブジェクトが無効化しないという最悪の場合には、再配置も実施する必要があります。そのため、時間計算量は𝑂(𝑛)です。ほとんどのオブジェクトは小さく、ヒープ走査中にいずれにしても出力ポインタ(outgoing pointer)を詳細に調べる必要があり、キャッシュ内にホットな状態で存在しているはずなので、コピーのオーバーヘッドは無視できる程度であると推測されます。それゆえ、mark-scavengeのコストはmark-evacuateのコストに比べてscavengingのコストに近いはずです。
実際には、パフォーマンスは実装固有の要因によって決定されます。
4 MS-ZGC: A Prototype Implementation of Mark–Scavenge in ZGC
markingとscavengingはヒープ上の有効オブジェクトの量に比例するため、大きなヒープではこれらの処理が長時間実行されることになります。これにより、オブジェクトの有効状態がコレクタに検出されないまま変化する可能性が高まり、無駄な再配置作業が発生する原因になります。ZGCはOpenJDK用のコンカレント・コレクタで、特に大規模ヒープを対象としています。ZGCはsnapshot-at-the-beginning アルゴリズムのマーク方式を使用しているため、マーク時間が長くなり、古い有効性情報が残る可能性があります。したがって、mark–scavenge方式に適していると考えられます。このセクションでは、ZGCにおけるmark–scavengeのプロトタイプ実装について説明します。この実装は、Mark-Scavenge ZGC(略してMS-ZGC)と呼んでおり、再配置をできるだけ回避するように試みています。MS-ZGCについて説明する前に、まずZGCコレクターの概要を説明します。このMS-ZGCは、OpenJDK 21でリリースされた最新の世代別ZGCアルゴリズムを基にしています。
4.1 ZGC in a Nutshell
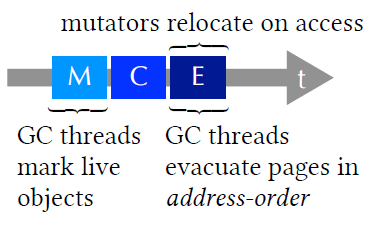
ZGCは、C4スタイルの世代別、領域別、並列、圧縮、同時実行のガベージコレクターです。その設計では、スループットの低下とスペースのオーバーヘッドの増加と引き換えに、レイテンシを低減しています。ZGC GCサイクルの各フェーズの概要はFig. 7の通りです。このサイクルはマーキング(M)から始まり、マーキング中に収集された有効性(C、マーク完了 [mark complete])に基づいて退避対象の領域を選択し、退避(E)で終了します。すべてのフェーズはミューテーターとの同時実行が可能で、GCスループットを向上させるために並列スレッドで実行されます。
ZGCは「ページ」と呼ばれる領域のメモリを管理し、そのページは3つのサイズクラス(small、medium、large)に分割されます。本稿では簡略化のため、smallページにのみ焦点を当てます。smallページは2MBで、16バイトから256KBのオブジェクトを格納します。
ZGCは、GCサイクルを基準としてオブジェクトの経過時間をページレベルの粒度で追跡します。オブジェクトの再配置の都度、経過時間𝑛のページから経過時間𝑛+1のページに当該オブジェクトをコピーします。動的に決まるオブジェクト有効期間のしきい値で、オブジェクトがyoung世代からold世代に昇格するタイミングを制御します。マイナー・コレクションでは、youngページ上のガベージのみを収集します。メジャー・コレクションでは、まずyoungコレクションのGCを開始し(オールド・ヒープのルートを計算します)、その後oldページ上のガベージを収集します。OpenJDKにおけるメモリーの初期化の技術的な理由により、GCサイクル𝑛で割り当てられたオブジェクトは、GCサイクル𝑛+1まで、マーキングにも再配置にも参加しません。
4.1.1 Concurrent Marking and Concurrent Evacuation.
マーキングはミューテーターと並列で動作し、snapshot-at-the-beginningマーキングを使用します。これは、マーキングの開始時に到達可能なすべてのオブジェクトが有効としてマークすることを保証します。マーキング中、ZGCはlivemapを生成するとともに、各ページの有効バイト数を計算します。マーキングが完了すると(C)、すべてのページを有効バイト数の多い順にソートしたリストに追加します。このリストから「再配置セット」が選択され、選択されたページを退避後、ヒープの総断片化が最大でも25%(young世代。old世代では5%)になるようにします。断片化は、有効バイトの量とページのサイズを比較することで計算します。古いオブジェクトの場所を新しい場所にマッピングするために、 forwarding table(転送テーブル)を再配置セット内の各ページに対して作成します。 その後、ZGCは並列スレッドを使用して再配置セット内のすべてのページの退避処理を行います。 ページの退避処理では、そのページのlivemapを繰り返し処理しながら、アドレス順にすべてのオブジェクトを再配置します。
ZGCはヒープに格納されたポインターに埋め込まれたメタデータで分岐するロード値バリアを使用して、退避をミューテーターと同期します。退避(E)が始まると、ヒープ内のすべてのポインターは無効になります。つまり、ポインターが指すオブジェクトが転送されたかどうかをアクセス時にチェックしなければなりません。オブジェクトは、(ミューテーターやGCスレッドによって)無効なポインターを使って初めてアクセスされたときに、退避用に選択されたページに存在していれば転送されます。無効なポインタが発見されると、その参照オブジェクトへの有効なポインタに更新されます。
E(退避)の終了時に、直近のマークフェーズで有効と判明したオブジェクトはすべて再配置されていますが、そのポインタはまだ再マッピングされていない可能性があります。これは次のマークフェーズで自動的に処理されます。具体的には、liveset内の検証されていないポインタをすべて発見し、新しい場所を指すように更新します。
4.1.2 In-Place Compaction.
コピーコレクタでは、退避中にオブジェクトが一時的に2つの場所に存在するため、メモリ消費が一時的に増加します。一般的に、オブジェクトはメモリが不足しているときに再配置されるため、コピー用の領域を確保する要求して失敗し、再配置の停滞を引き起こす可能性があります。ZGCはこの問題を、インプレース圧縮に戻す、つまり、退避のためのターゲット・ページがソース・ページそのものになることで処理します(§2.3)。これにより、退避はfrom-spaceページに書き込まれることになり、そのページ上の移動オブジェクトとのデータ競合を避けるために、同じページへのすべてのアクセスをブロックする必要があります。これは、ZGCがGCアクティビティでプログラムスレッドにブロックを強いる唯一のケースであり、レイテンシに敏感なワークロードには望ましくありません。これは、レイテンシに敏感なワークロードには望ましくありません。適切に設定されたデプロイメントでは、GCには十分な余裕があり、このようなことは決して起こらないはずです。
4.1.3 Frequency of GC Cycles.
ZGCは、控えめな推定に基づくヒューリスティックを使用して、GCサイクルを開始するタイミングを決定しようとします。ここでは、GCサイクルを開始するための最も一般的なトリガールールである、マイナーコレクションの割り当て率ルールに焦点を当てます。
このルールは、ヒープ上の空き領域の量を計算し、控えめに割り当て率を推定して、さらに完全なGCサイクルを完了する時間を控えめに推定します。さらにGCを実行するGCワーカーの数を計算します。ワーカーの数が少なくても十分な時間がある場合は、ミューテーターをできるだけ妨害しないようにするため、この方が好都合です。次に、これらの数値を使用して、選択したワーカー数でGCサイクルを実行する時間と、割り当て率と利用可能なメモリに基づいてOOMまでの時間を予測します。OOMまでの時間がGCまでの時間より少なくとも5%長ければGCを延期し、そうでなければGCを開始します。GC用のスレッド数は、サイクル中に上下に調整できるので、例えば突然の割り当てスパイクにも対応できます。
4.2 MS-ZGC in a Nutshell

mark–scavengeをZGCに統合してMS-ZGCを作成する方法を説明するために、ZGCについて十分に理解する必要があります。Fig. 8は、MS-ZGCのフェーズの概要を示しています。各サイクルは、前のサイクルで選択されたページの退避とマークの組み合わせ(M)から始まり、マークの完了(C)が続き、退避(E)が開始されます。ZGCとは異なり、GCワーカーはページを退避させません。ただし、退避対象として選択されたページ上のオブジェクトに対するミューテーターのアクセスにより、ミューテーターがオブジェクトを再配置します。これらのページ上の到達可能なオブジェクトは、次のサイクルのマークフェーズで再配置され、ページが退避されて再利用可能になります。Eフェーズ中にメモリ圧力が高まった場合は、新しい割り当てを行うために、アドレス順の退避が使用されてページが再利用可能になります。mark–scavengeの理解を促進し、比較を容易にするため、私たちは実装においてZGCをできるだけ変更しないように努めました。私たちは、OpenJDK 22のMS-ZGCを、コミット49fff0132bbで作成しました。このパッチは1485行を挿入し、121行を削除します。すべての変更の54%は、OpenJDKのZGCディレクトリにあります。変更をより集中化しようと試みた結果、ほとんどの変更は次の3つの新しいファイルに収められています。
zFromSpacePool.hpp(162行)zFromSpacePool.cpp(469行)zFromSpacePool.inline.hpp(119行)
4.2.1 The From-Space Pool.
mark–scavengeをZGCのyoung世代にのみ追加します。old世代のオブジェクトは消滅する可能性が低く、したがって無駄な再配置作業につながる可能性も低いからです。mark–scavengeがold世代に与える影響については、今後の課題として調査を継続します(したがって、Fig. 8のフェーズEの間、GCワーカーはold世代に昇格されるyoung世代のページを退避させます)。young世代では、遅延可能ページ(deferrable pages)の概念を導入します。ページが避難対象として選択された場合、そのページは遅延可能とみなされ、young世代からold世代への昇格は行われません。遅延可能ページは、from-spaceプールを構成します。したがって、from-spaceプールは、ZGCでは積極的に退避されるはずのyoung世代のすべてのページを表しますが、mark-scavengeでは退避を遅らせ、これらのページ上のほとんどのオブジェクトが無効になって移動する必要がなくなることを期待します。理想的なケースでは、from-spaceプール内のページはページ割り当てに必要なくなり、プール内のページ上のオブジェクトは次のマークの前に到達不能になります。ZGCの退避フェーズを変更して、遅延可能ページをスキップするようにします。Eの開始時点から、遅延可能ページ上のオブジェクトへのアクセスがあると、アクセス前にオブジェクトを再配置します(§4.1.1参照)。アクセスされないオブジェクトは、
- 次のGCサイクルまで、または
- 現在のサイクルでシステムがメモリ不足に近づくまで、
ページ上に残ります。
(1) その後のMフェーズでは、到達可能な遅延可能ページ上のオブジェクトが再配置されます(Fig. 6、69行目)が、これは
- ZGCのバリアを変更
- 再配置されたオブジェクトのアドレスを再マッピング
- これらのページでも再配置を実行
して実現します。この変更は単純明快です。from-spaceプール内のすべてのページは遅延可能であるため、その後のマークフェーズの終了時には、プール内のすべてのページが完全に退避されます。ページの最後のオブジェクトが再配置された際に、そのページが完全に退避されたことを検出できるように、ページのforwarding tableで2つの値を追跡します。その値とは、有効バイト数(前のマークフェーズで計算)と退避バイト数(前のマークフェーズの終了以降)です。退避のたびに後者の値を増やします。退避バイト数が有効バイト数と等しくなると、ページは完全に退避されたことになります。この状態になると、そのページを(CPUごとの)空きページのリストに追加します。
(2) メモリ不足の状況に対処するために、from-spaceプールのページから割り当てできるようにします。空きページの割り当てに失敗し、システムの空きメモリが枯渇した場合、割り当てが停止する前に、以下の順序で割り当てを試みます。
- 現在の CPU の空きページのリストから割り当てを試行します。
- 失敗した場合は、他のすべての CPU の空きリストから割り当てを試行します。
- それでもだめなら、from-space プールの中で最も使用率の低いページを選択し、それを退避して、空きページとして返却する(§4.2.2 を参照)。
特に最後のケースでは、古い有効性情報に基づいて再配置を実行するため、無駄な再配置作業が発生する可能性があります。
4.2.2 Allocation in the From-Space Pool.
メモリ不足時は、from-spaceプールからページ割り当てを行う可能性があります。その場合、プール内で最も使用率の低いページを選択して退避させることになります。退避はZGCのロジックに従います。すなわち、
- livemapに従ってページ上の有効オブジェクトのアドレスを順にたどる
- 適切な経過時間とともに、まだターゲットページ(下記参照)の空き領域に再配置されていないすべてのオブジェクトをコピー
- forwarding tableに新しい場所を記録
このロジックは、既存のZGCインフラストラクチャを使用して25LOCで実装されています。(Fig. 5aのjit_evacuate()関数がこれにあたりますが、簡略化のためageは無視しています)。from-spaceプールには、プール内での避難のみに使用されるさまざまなageのターゲットページが含まれています。簡略化のため(および mark–scavengeと直交するため)、ターゲットページは2つの方法で作成します。
- 再配置フェーズ開始時に、システムから空のページを割り当ててターゲットページとして利用する。プール内にあるageのページのみ割り当てる。
- from-space内でのインプレース圧縮
実装の初期のイテレーションでは、from-spaceプール内での最初の退避により、ターゲットとして使用する適切なageのページが1つ追加でインプレース圧縮されました。これがメモリ不足につながることは保証されていませんが、インプレース圧縮中に変更者がページ上のオブジェクトにアクセスしようとした場合、レイテンシに悪影響を及ぼします(§4.1.2参照)。 経過時間ごとの空のページから開始することで、インプレース圧縮のほとんどを回避できます。
from-spaceプールは同時割り当てをサポートしていますが、ZGCではページ割り当てがロックで保護されているため、現時点ではこの並列性をシステムに公開していません。システムが飽和状態になり、連続したGCを行う場合、このロックの外側からfrom-spaceプールからの割り当てを移動させることで、割り当てが必要なスレッドが「GCを支援」できるようになり、パフォーマンスが向上することがわかっています。ロック設計を維持する理由は、比較を容易にするためにZGC設計に近づけるためです。ZGCページアロケーターが割り当てリクエストを満たそうとする順序を維持したい場合、ロック外のfrom-spaceプールで割り当てを移動させることは、単純なことではありません。
from-spaceプールの最も密度の低いページから開始することで、密度の高いページ上のオブジェクトの再配置をさらに遅延できます。この方式のデメリットは、from-spaceプールへの割り当て時間が増加するだけでなく、from-spaceプール内のターゲットページに避難するオブジェクトが増えるため、解放される実質的なバイト数が減少することです。
プロトタイプ実装では、ZGCページ割り当てロジックに従っています。ZGCではミューテータースレッドがページをリストから削除するか、システムにメモリを要求してページを割り当てます。MS-ZGCでは、from-spaceプールからページを割り当てるミューテーターは、そのページ上の残りのオブジェクトを退避させる必要があります。この問題に対する代替策としては、
- 部分的な退避(例えば、1回の割り当てバッファ)のサポート
- OOMの直前に退避を実行するGCワーカーの使用、および/または
- 割り当て率を一致させる
ことまで、さまざまなものがあります。from-spaceからの割り当てを最後の手段としてのみ実行するため、ミューテーターがページ内の多くの有効オブジェクトを移動する可能性が高いです。これにより、ページの退避に必要な作業が軽減するとともに、残存する無効オブジェクトをクラスタ化し、次のサイクルで再利用される可能性が高くなります。
4.2.3 Interfacing with ZGC Heuristics.
ZGCのメインコードをできるだけ変更しないために、私たちは、退避も退避先への移動もされていないfrom-spaceプール内のすべてのページを空きページとして報告します(詳細は後述)。したがって、ZDirectorスレッドがヒープサイズをサンプリングすると、ZGCヒューリスティクスには、ZGCで積極的に退避されるはずだったすべてのページが回収されたように見えます。これにより、GCサイクルを開始するタイミングを決定するためにZGCのヒューリスティックを再利用できるようになります(この変更を行わない場合、ヒューリスティックの修正を行わないと、各GCサイクルの明らかな非効率性により、GCサイクルがより早く開始されてしまいます)。直観的には、from-spaceプール内のページは、まだ退避されていない場合でも、事実上利用可能であるということです。from-spaceプール内のページが退避されると、プールから削除されます。これにより、プールが報告する空き領域が減少すると同時に、空きページが利用可能(空き)ページのリストに追加されます。
プール内のページをto-spaceのページとして使用すると(Fig. 5aのjit_evacuate()の111行目のように、他のページをto-spaceのページに退避する)、同様に削除されます(が、利用可能なページのリストには追加されません)。
from-spaceプール内のすべてのページが利用可能であると報告すると、実際の空きバイト数が実際よりも多くなる可能性があります。一方、遅延退避の影響により、退避フェーズの開始時に空きバイト数を報告するだけでは、利用可能なメモリが実際よりも少なくなる可能性があります。そこで私たちのアプローチでは、遅延可能ページ上のオブジェクトの有効率に関する履歴データを使用し、直近のGCサイクルで回避された再配置を活用できるようにします。
free_bytes_in_fsp = deferrable_pages · 𝑝𝑎𝑔𝑒_𝑠𝑖𝑧𝑒 · (1 − (survival_rate + variance))
ここでsurvival_rateは、from-space プール内の有効バイトの生存率の減衰平均に、保守性を考慮したこの数値の分散を加えたものです。どの程度積極的に減算を行うべきかを理解するのは容易ではないため、上記の公式は改善の余地があると考えています。
メジャー・コレクションに関して言うと、ZGCはマイナー・コレクションに費やされた平均時間とマイナー・コレクションによって返却されたメモリーの平均量を確認し、old世代に高いメモリー圧力がかかっていない場合でも、メジャー・コレクションを起動するかどうかを決定します。この数値は free_bytes_in_fsp とは異なる方法で取得され、GC サイクルごとに1回だけ取得されます。単純化のため、ZGC のロジックに従って解放されたバイト数(再配置セット内のすべての遅延可能ページ上のすべての解放済みバイトの合計)を報告します。
4.2.4 Livemap Management.
livemapはマーキング時に計算されます。ZGCでは、前のGCサイクルからの再配置はすべてこの時点で行われ、古いlivemapは破棄されます。これに対して、MS-ZGCでは、前のサイクルからのlivemapをマーキングの期間中保持し、メモリ圧力が高い場合にページをインアドレス退避できるようにしています。簡単にするため、プロトタイプ実装では、マーク完了段階ですべてのlivemapのコピーを作成します。これは最適な設計ではなく、ページが初めてアクセスされる直前のマーク中にlivemapを遅延コピーすべきです。マーク中に完全に退避したページだけがlivemapを必要とするため、すべてのページがlivemapのコピーを必要とすることになるとは限りません。さらに、すべてのlivemapをコピーするには時間がかかり、マーク完了フェーズ(Fig. 8のC)で費やされる時間は、このフェーズではメモリ断片化解消作業ができないため、最小限に抑える必要があります。後続のマークフェーズ中の遅延コピーを実装したパッチに関する、Fig. 13のポジティブな効果を確認してください。
5 Evaluation
まず、我々の予想を見直すことから始めましょう。オブジェクトが退避するまでの遅延を増加させ、また、退避を実行するために有効性を計算し、その有効性情報に基づいて対処するまでの遅延を減少させることで、より少ないオブジェクトを再配置することにつながるため、全体としてGCを実行するのに必要な作業量を減少させることが期待されます。これは、ベンチマークにおいて以下のように現れるはずです。具体的には、私たちのZGCベースラインと比較した場合、特に再配置フェーズのレイテンシ(§5.5)とフェーズ時間(§5.7)が短くなるはずです。しかし、これはfloating garbageの量やヒューリスティックスのチューニングの必要性に依存し、すべてのベンチマークで実現するとは限りません。GC作業がパフォーマンスのクリティカルパス上にある場合、GC作業の削減はパフォーマンス向上として現れるはずです。十分な余裕がある場合は、アプリケーション性能への影響は期待できません。
Performance Metrics(パフォーマンス指標):アプリケーションのスループットと応答時間を報告します(利用可能な場合)。さらに、MS-ZGCの性能をより完全に示すために、キャッシュミス、およびマイナー/メジャーGCサイクルのwall-clock time(実際の経過時間)を報告します。GCサイクルをいつ呼び出すかを決定するヒューリスティックと同様にワーキングセットも影響を受けるので、old世代のGCサイクルとyoung世代のGCサイクルの量も測定しました(§5.6)。各GCサイクルについてOpenJDKの組み込みメトリックを使用してGCサイクルの期間を記録しました。
5.1 Experimental Setup
データ収集を迅速化し、合理的な時間内に大量のサンプルを収集するために、コンピュータークラスタ内の複数の同等ノードでベンチマークを実行しています。ベンチマークの異なる呼び出しは、異なるノードで実行される可能性があります。クラスタの各ノードには、Intel Xeon E5 2630 v4(25 MB L3キャッシュ、ECC 2400MHz DIMM DRAM)が装備されています。ノードはCentOS 7で稼働しており、構成は同一です。マシンでは同時マルチスレッド(simultaneous multi-threading、SMT)は無効化、周波数スケーリングは有効化されていました。
5.2 Statistical Methodology
Georgesらの文献に従い、DaCarpoのような反復的なワークロードを伴うベンチマークでは、JVM実行ごとの直近の5回のiterationのスループットを使ってウォームアップ時のばらつきを低減しています。最初の5回のiterationを無視してレイテンシをプロットします。その他のメトリックは全て全iterationで収集しています。最も長期間実行するベンチマークを除き、各JVMの実行で20回のiterationを実施しました(iterationの観点ではウォームアップが速くなります)。ログファイルのサイズのため、Kafkaベンチマークでは10回のiterationだけを実行しますが、ばらつきが少ないので、この10回の実行が結果には影響しないと考えています。JVMの実行で自然に発生するばらつきを排除するために、1つのベンチマークにつき120点の個別のJVM実行でデータを収集します。このように、有意性を推測するための大量のデータセットを用意しています。SPECjbb2015ベンチマークでは、ばらつきが低いためVM呼び出しを60回実行します。このベンチマークの各実行にはiterationが1回のみ含まれています。このiterationの中で、2時間のタイムウィンドウ内でマシンに負荷をかけ続け、そのマシンの限界に達するまで繰り返し測定を行います。
2種の異なるデザインを比較するため、ZGCとMS-ZGC間でばらつきが同じであると仮定するのはリーズナブルではありません。そのため、Welchのt検定を使い、統計的有意性を検証します。レイテンシの百分位数(パーセンタイル)のプロットのエラーバンドは10,000個のブートストラップのサンプルを使ったブートストラップ法を使って推定しています。
5.3 Benchmark Selection
SPECjbb2015、および DaCapo(23.11-chopin)の 2023 年リリースの全ベンチマークを使用しています。SPECjbb2015 のcompliant実行(デフォルト)だと、マシンに徐々に負荷を与えて待ち時間とスループットを測定し、マシンに負荷がかかりすぎてSLAを満たせなくなった時点で停止するというシナリオです。待ち時間のベンチマークにとって興味深いシナリオはこれが唯一というわけではありません。低レイテンシサービスのデプロイメントでは、通常、GCによるストールを回避するために、CPUのヘッドルームを十分に残すため、今回は、compliant実行だけでなく、70%の注入率、すなわち、与えられたヒープサイズにおいてマシンが処理可能な最大作業負荷の70%での評価も同時に実施しました。
SPECjbb2015ベンチマークは、critical-jOPSと呼ばれる待ち時間スコアを報告します。このベンチマークは、特定のSLAをどの程度の作業負荷で満たすことができるかを探ろうとするものです。このスコアは、さまざまなレイテンシ要件の幾何平均から導出されているため、今回は各SLAについて個別の結果を報告します。レイテンシを気にする人にとっては、より緩やかな要件だけでなく、最も厳しい要件が改善されていることを知る方が有益だと思ったからです。
tradebeansとtradesoapはJDK 21以上では動作しないため、省略せざるを得ませんでした。さらに、jmeベンチマークはCPU使用率が1コア以下であり、大きなワークロードサイズに必要なヒープが100MB未満であるため、レイテンシ調査のために除外しています。ワークロードサイズlarge(largeが利用できない場合はデフォルト)を使用して、すべてのベンチマークを実行しました。
5.3.1 Heap Sizes.
与えられた作業負荷に対して、異なるヒープサイズでGCアルゴリズムが異なる性能を発揮する可能性があることはよく知られています。このことは、複数のヒープサイズで性能評価を行うことの重要性を強調しています。さらに、割り当てストール(stall、停止)はレイテンシにとって最悪です。ZGCでは、割り当てストールが発生すると、
- ミューテーターはGCワーカーのプールにシグナルを送り、次にワーカーがメモリーを解放したときに緊急にメモリーを提供し、それが発生するまでスリープする、もしくは
- 現在GCが実行されていない場合はGCの開始を要求し、ワーカーがメモリを提供するまでスリープ
します。このプロセスのラウンドトリップタイムは数百から数千ミリ秒になるため、低レイテンシが要求されるアプリケーションでは、このようなイベントが可能な限り発生しないようにヒープのサイズを決める必要があります。その目的のため、各ベンチマークで(少なくとも)2つのヒープサイズを選択します。1つは十分なヘッドルームを持つもの(妥当なデプロイメント)、もう1つはそうでないもの(設定ミス)です。後者はストールに悩まされる可能性が高いでしょう。ZGCのようなconcurrent GCを使用する時空間コストを相対化するうえで役立つよう、ZGCとMS-ZGCと同様に、デフォルトコレクタG1の最小ヒープサイズを測定したので、その結果も提示します。これらの結果はTable 2にあります。
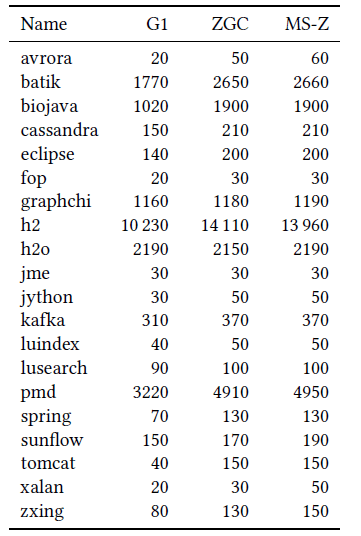
5.3.2 Finding Heap Sizes.
ストールが発生するヒープサイズを見つけるために、ストールを回避する十分なヘッドルームがあると思われるヒープサイズから測定を始めました。そこからヒープを縮小し、少なくとも30回のVM呼び出しを行いました。これらのVM呼び出しの間、平均ストール回数が1回未満であれば、ストールしない(stall-free)ものとみなしました。ストールしやすいヒープに到達する前の最後のヒープを正常ヒープと呼ぶことにします。その時点から、ヒープを60%縮小することによって、タイト(あるいはストールしやすい)ヒープを見つけました。 アプリケーションとGCの組み合わせに対する最小ヒープサイズを見つけるために、10MB刻みで検索しました。10回の連続VM呼び出しが OOM なしで実行される最小ヒープを、最小ヒープとみなします。SPECjbb2015 のcompliant実行は作業負荷を動的にサイズ決定するため、最小ヒープという概念はなく、ヒープサ イズを求める方法は適用できません。このアプリケーションでは、ベンチマークでマシンが飽和してしまうため、CPU コア当たりの メモリサイズ(GB)を推論するのが理にかなっています。コアあたりのメモリ(GB)が制限されすぎると、ストールにつながります。利用可能なコア数の1.6倍、2.4倍、3.2倍でヒープを評価しました。
5.3.3 Number of threads.
スレッド数は明示的に設定せず、ベンチマークに事前定義された動作を使用しました。Table 3に、JVM が報告した、DaCapo ベンチマークで使用した平均 Java スレッド数(つまり非VM)を示します。SPECjbb2015では、平均スレッド数は360でした。スレッド数は、ヒープ・サイズの影響を受けませんでした。
5.3.4 Behaviour metrics.
メモリの再利用を遅らせていることから、GC サイクルのトリガーとなるヒューリスティックスに影響します(§4.2.3参照)。そのため、サイクル数を測定します。作業セット(working set)のサイズも変更しているため、サイクルのwall-clock time(実際の経過時間)が変化することが予想されます。オブジェクトの配置が異なる可能性があるため(アドレス順とオブジェクト・グラフ順)、キャッシュ・ミスを記録しておきます。GCスレッド数の計算が影響を受けるため、task-clock(CPU時間)を計測します。さらに、有効作業セットが変更されると、ZGCの動的昇格しきい値(dynamic promotion threshold)が影響を受ける可能性があるため、young世代とold世代のサイズも記録します。
5.3.5 How to Read Our Tables and Figures.
表中、緑と赤のセルは結果が統計的に有意であることを示しています。散布図では、点はその結果が統計的に有意であることを示し、十字はその反対であることを示します。最後に、レイテンシプロットでは、バンドは95%信頼区間を示すので、バンドが重なっていないということは、その結果が統計的に有意であることを意味します。
5.4 How we Obtained the Results in Fig. 2
OpenJDKでは、G1とSerialともに、GCサイクルの各段階で、特定のageにおける有効バイト数を表す”age table”の出力をサポートしています。この表から、GCサイクル𝑛におけるage 𝑎への昇格数と、その後のGCサイクルn+1におけるage 𝑎 + 1の有効バイト数を計算できます。<age 𝑎での有効バイト数> − <age 𝑎 + 1での有効バイト数>までのマークまで退避を遅延できれば、退避がまったく不要になるバイト数の割合を計算できます。
ZGCにはage tableに相当するものがないため、独自のテレメトリデータを追加して、これらの結果を取得します。GCサイクル𝑖で退避を開始する前に、退避する予定のバイト数をグローバル変数𝐸𝑖に記録します。各ページについて、そのページ上の各オブジェクトの有効状態を追跡するlivemapを、そのページに再配置されたオブジェクトのうち、その後のGCサイクルで有効ではないオブジェクトを追跡できるようにするためのdeadmapで補完します。
オブジェクトをページにコピーすると、deadmap内の当該オブジェクトのステータスを1に設定します。その後のGCサイクル𝑖 + 1では、マーキングでこのステータスを0に変更し、グローバル変数𝑀𝑖がオブジェクトのサイズ分だけインクリメントされます。サイクルの終了時、𝐸𝑖 − 𝑀𝑖 は、退避されたオブジェクトの総サイズから、その後に有効とマークされたオブジェクトの総サイズを差し引いた値を表します。また、deadmapは、前回のサイクルで退避されたオブジェクトのうち、その後のマークで到達不能となったオブジェクトを正確に示します。オブジェクトを有効状態とマークする複数のワーカースレッドは、オブジェクトの状態をdeadmap上で1から0に正常に反転させたスレッド内のオブジェクトの𝑀𝑖のみをインクリメントすることで処理されます。
ZGCのロードバリアに基づく設計を活用し、コピー時点で既に事実上無効の再配置オブジェクトの数を把握するための、2つ目のテレメトリを追加できます。この設計では、その後のマークフェーズにおける有効状態は考慮せず、退避オブジェクトが退避後にアクセスされるかどうかを調べます。退避フェーズにおける最初のミューテーターのアクセスにより、ロードバリアのslow-path(低速パス)がトリガーされるため、このイベントを測定し、”access map”に変更アクセスを記録します。ZGCはsnapshot-at-the-beginning (SATB) マーキングを使用しているため、マーキング開始後のアクセスを記録する意味はありません。到達不能なオブジェクトの発見可能性はスナップショットの時点で確定しているためです。マーキング終了後、アクセスマップを使用して一度もアクセスされなかったオブジェクトを調べ、その中から到達不能であることが判明したオブジェクトをクエリします。“dead on relocation”(再配置時に無効)を測定するために必要なインストルメントには、パフォーマンスに影響を与える高いオーバーヘッドがあります。そのため、Fig. 2とFig. 3の実験結果は、このセクションで報告されている主な結果とは別に収集されたものであり、また、24コア、32ハードウェアスレッド、およびより大きなキャッシュを備えた、より新しいマシン(Intel i9-13900K)でも収集しました。これらの違いにより、割り当て率と回収率がともに高くなり、その結果、ヒープサイズも異なります。Table 3およびTable 4に記載のコンピュータークラスタよりも、このマシン(Fig. 2およびFig. 3)の再配置の回避量が著しく高いことに注目してください。詳細については、補足資料を参照してください。
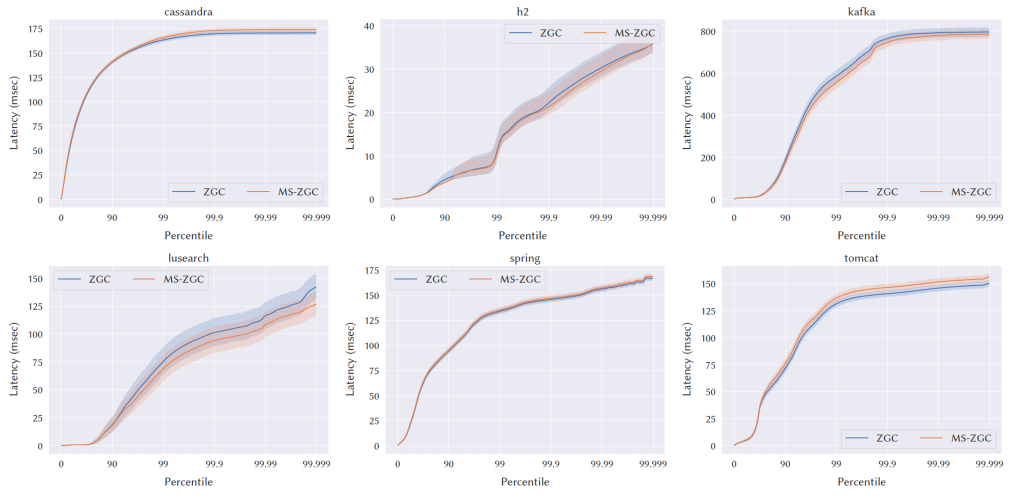
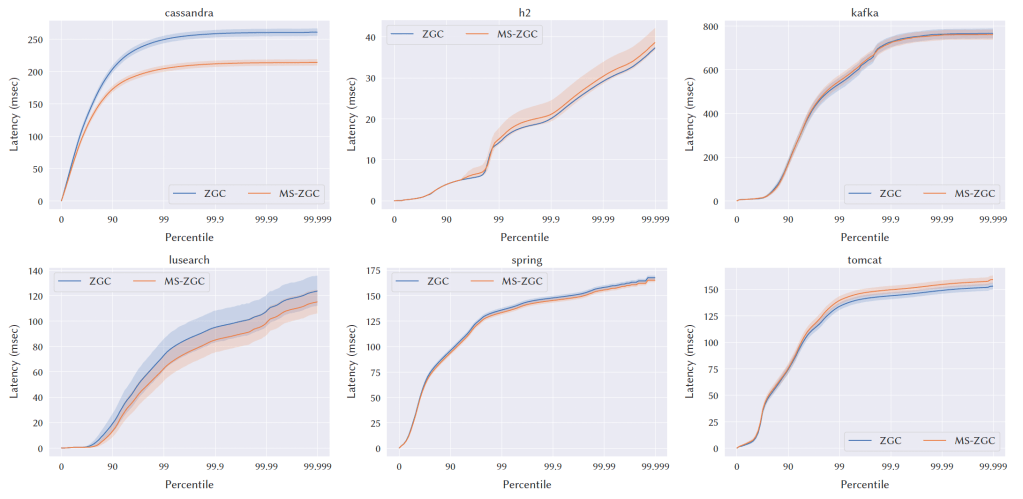
Fig. 10. Latency results for DaCapo with a tight heap.
5.5 Latency Impact
図9から図10は、DaCapoのレイテンシの結果です。ノーマルヒープではレイテンシに変化は見られませんが、タイトヒープでは、99パーセンタイル、99.9パーセンタイル、99.99パーセンタイル、最大パーセンタイルで、Cassandraのレイテンシが20%削減されました。SPECjbb2015のcritical-jOPSスコアは2~4%改善されました。最も厳しいSLAである10ミリ秒の場合、16GBではcompliant実行で3.3%、最大注入率の70%の実行で4.2%のレイテンシの改善が見られました。24GBと32GBでは、compliant実行では変化が見られませんでしたが、最大注入率の70%の実行では1%前後の小さな改善が見られました。その他のSLAについては、すべてのヒープサイズで1~5.5%の統計的に有意な改善が見られます。
5.6 Performance Impact
Table 3からわかる通り、DaCapoベンチマークでノーマルヒープについて、10個のアプリケーションには影響がなく、(2.8%の劣化が見られたsunflowを除き)8個のアプリケーションには0.21から1.5%の劣化が見られました。pmdは1.83%の改善が見られた唯一のアプリケーションでした。以前の研究で、sunflowではオブジェクトの割り当て順を維持することがパフォーマンスにとって極めて重要であることが示されています。そのため、MS-ZGCがリロケーションを線形からグラフ順に変更したため、最も大きな後退が見られたとしても驚くことではありません。
DaCapoでタイトヒープを使用した場合、8個のアプリケーションには影響がありませんでしたが、9個のアプリケーションで劣化が見られました。h2とtomcatのベンチマークでは、0.11~0.14%のわずかな改善が見られました。スループットの劣化は、特にcassandra、fop、h2oなど、一部のアプリケーションでより顕著でした。これは、プロトタイプでページロックによるfrom-spaceの割り当てのシリアライズが原因で劣化が発生したと考えています(§4.2.2参照)。当然ながら、同時並行アプリケーションのスループットに悪影響を及ぼします。Table 4は、SPECjbb2015の結果を示しています。スループットスコアのmax-jOPSは、最小の16GBのヒープでは影響を受けませんでしたが、24GBのヒープでは7.7~7.8%の大幅な改善が見られました。32GBのヒープでは、compliant実行で1.81%、最大注入率実行の70%で2.97%の改善が見られました。SPECjbb2015はマシンを飽和させるため、GCがパフォーマンスのクリティカルパスになります。というのも、ミューテーターとGCワーカーがCPUを競合して作業を行うからです。GCがパフォーマンスのクリティカルパスとなります。MS-ZGCは、40~50%のyoungオブジェクトの再配置を回避するため、GCはより高速に実行され、GCサイクルをより多く実行できるようになり、同じ時間でより多くのオブジェクトを解放できるようになります。ヒープサイズが増加すると、GCのパフォーマンスはプログラムのパフォーマンスにとってそれほど重要ではなくなるため、GCの効率が改善しても、小規模なヒープほどスコアが向上するわけではありません。
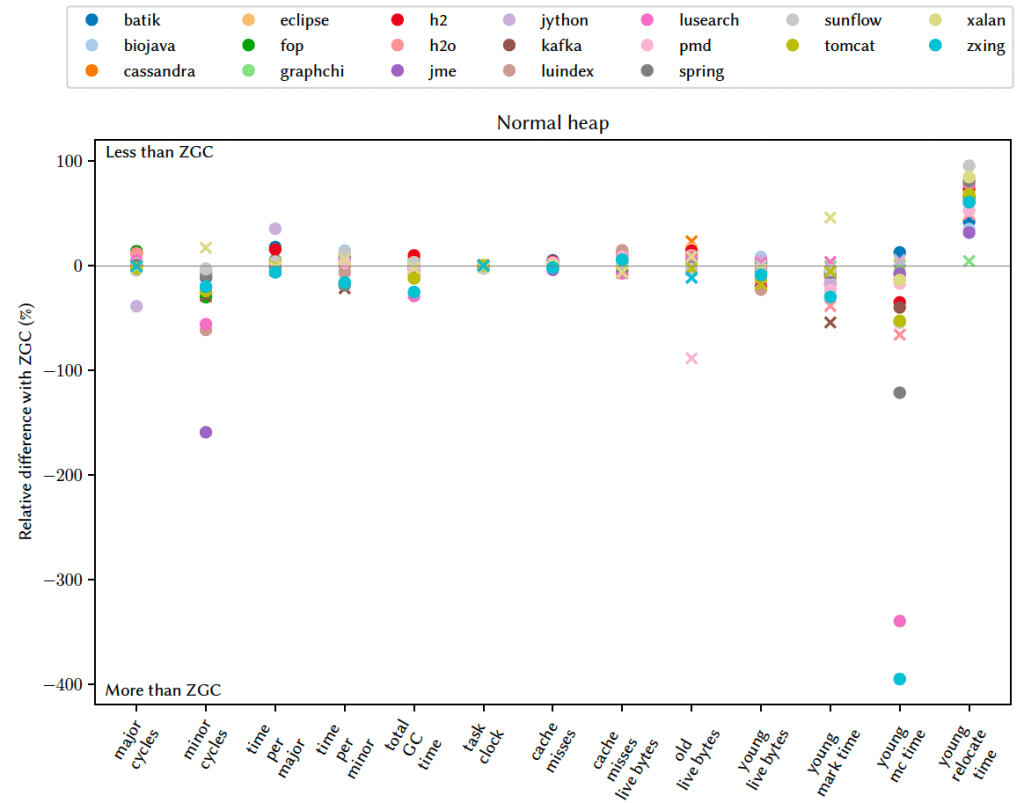

Fig. 11. Comparison of GC Behaviour Metrics
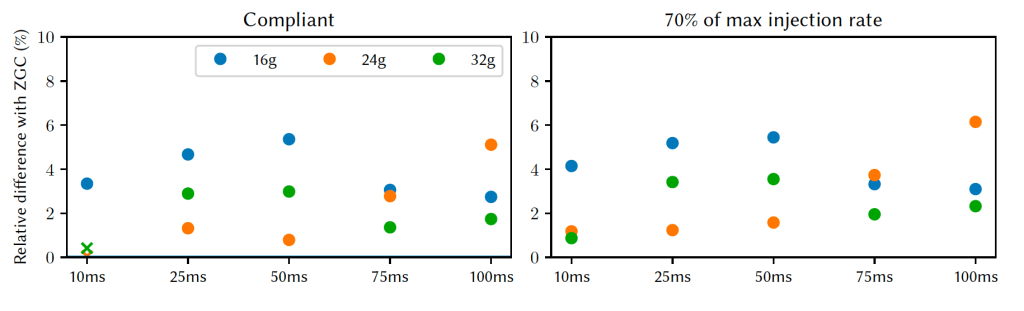
Fig. 12. Max jOPS for different SLAs in SPECjbb2015
5.7 Effect on GC Behaviour
Fig. 11では、大半のベンチマークにおいて、メジャーサイクルの回数が0.67~21.86%の範囲で減少していることを示しています。一方、マイナーサイクルの回数は2.91~159.15%の範囲で増加しています。Avroraは、通常のヒープではマイナーが460%増加し、タイトヒープではマイナーが12,000%増加しており、両方で極端な異常値を示しています。AvroraでなぜGCヒューリスティックがおかしくなったのかを特定できませんでしたが、ヒューリスティックがここまで誤っているため、表からAvroraを除外しました。興味のある読者のために、補足資料にはAvroraの結果も記載しています。各サイクルのwall-clock time(実際の経過時間)におけるコストは、ノーマルヒープ、タイトヒープではメジャーGCで削減されますが、マイナーGCについては、タイトヒープにおいて削減されていました(一部ノーマルヒープでも削減されていました)。全体的なサイクルの実行数は増加する傾向にあるため、GCに費やされるwall-clock timeはどちらのヒープサイズでも増加します。アプリケーション全体に割り当てられたtask-clock(CPU時間)をperfで測定したところ、ノーマルヒープでは違いがなく、タイトヒープではわずかに増加しています。
再配置をアドレス順からグラフ順に変更したにもかかわらず、キャッシュミスの傾向は強くありません。9件ではキャッシュミスが少なく、10ではキャッシュミスが多くなっています。タイトヒープのCassandaは特に悪い結果です。マーキングはキャッシュミスの主な要因であるため、この数値から結論を導くのは困難ですが、私たちはキャッシュミスが有効バイトの量に対してどの程度発生しているのかも測定しました。そのコンテキストでは(Fig. 11の cache misses live bytes を参照)、通常のヒープでは7件の改善と2件の劣化がみられました。特に、luindex、h2、eclipseでは、有効バイトに対するキャッシュミスの減少が10~15%でした。タイトヒープでは、7つの改善と4つの後退が見られます。Cassandraでは、有効バイトに対するキャッシュミスの大幅な減少が19%で、eclipseとluindexでは12~14%減少しました。old世代の有効バイトとyoung世代の有効バイトの削減と増加には、明らかな傾向は見られませんでした。退避フェーズのwall-clock time(実際の経過時間)は、ノーマルヒープでは平均64%、タイトヒープでは平均63%削減されました。マーク完了(C)フェーズに費やされた時間は大幅に増加しました。これはlivemapのコピー(§4.2.4参照)によるものです。残念ながら、この実装上の欠陥を発見するのが遅れたため、本論文の主な結果に修正を加えることができませんでした。しかし、livemapのコピーを無条件に事前に行うのではなく、必要に応じてジャストインタイムで行うように変更するように変更したパッチの効果を評価しました。その効果を示したのがFig. 13です。これによりこのフェーズの時間が大幅に改善され、マイナーコレクションおよびメジャーコレクションのコストがサイクルあたりで低くなりました。予想通り、作業を退避からマーキングにシフトしたことで、マーキングに費やす時間が増加しています。

Table 3. Performance and (avoided) wasted work in DaCapo. Threads denote the average number of Java threads in each benchmark. Heap sizes are in megabytes. E.time denotes execution time (throughput) normalised against ZGC. A.max denotes the avoidable bytes in gigabytes defined as the sum of live bytes on all deferred pages on all GC cycles. A.act denotes the actual relocated gigabytes avoided, i.e., the avoidable bytes that were not relocated. % denotes A.act / A.max. † see §5.7 for an explanation of why avrora numbers are missing.
(DaCapoにおけるパフォーマンスと(回避された)無駄な作業。
– スレッド:各ベンチマークにおけるJavaスレッドの平均数
– ヒープサイズ:メガバイト単位
– E.time:ZGCに対して正規化した実行時間(スループット)
– A.max:全GCサイクルにおける全ディファードページのライブバイトの合計として定義される、ギガバイト単位の回避可能バイト
– A.act:回避された実際の再配置ギガバイト、すなわち再配置されなかった回避可能バイト
– %:A.act / A.max
avroraの数値が欠落している理由については§5.7を参照のこと。)

Table 4. Performance and (avoided) wasted work in SPECjbb2015. Average number of threads was 360.

Fig. 13. The effects of moving copying of livemap from mark-complete to on a need basis in mark phase.
5.8 Reduction of Wasted Relocation Work
Table 3とTable 4において、%列はAvoided(再配置を回避したもの / A.act)をAvoidable(再配置回避可能なもの / A.max)で割って算出したものです。Avoidableは全ての遅延可能な有効バイトの合計です。SPECjbb2015とcassandra(タイトヒープ)は1回の実行につき、平均で100GB以上の回避に成功しています。これらはMS-ZGCの最も優れた結果が得られたベンチマークでもあります。使用するヒープに関係なく、MS-ZGCではDaCapoで回避可能なバイト数の23%のコピーのコピーに成功しています。SPECjbb2015では、ワークロードやヒープに関係なく、平均で48%と大幅に高い値になりました。
5.9 Fusing Marking and Relocation
Fig. 13で、マーキングに費やした時間がどうなったかを示しています。
削減:9個のベンチマーク
変化無し:4個のベンチマーク
増加:1個のベンチマーク
マーキングと再配置のコストがマーキング単独のコストに比べて高価であるとという因果関係は証明できませんが、少なくとも再配置されるオブジェクトの削減により隠れているようです。これは適切に構成されたシステムで大幅な後退は観察されないためです。これは、既存のマーク・パスにコピーを追加するコストが小さいか、無視できるほど小さいことを示唆していると考えます。
5.10 Analysis
程度の差こそあれ、すべてのアプリケーションで、無効オブジェクトであるにもかかわらず、GCがそのオブジェクトをコピーしていることを、に当てはまることがわかりました。MS-ZGCは、こうした無効オブジェクトの多くをコピーしないようにできます。xalanの場合、MS-ZGCはyoungオブジェクトの87~89%のコピーを回避していますが、絶対量はわずか0.35~0.75GBです。h2の場合、回避されたGBの量は41~59GBですが、これは候補バイト全体のわずか14%です。パフォーマンスの改善も示されていません。
ノーマルヒープのCassandraの場合、40%の回避を実現していますが、これは68GBに相当します。一方、タイトヒープの場合、相対的にはほぼ同じ回避を実現していますが、絶対値では200GB程度です。SPECjbb2015では、39~58%の回避を実現しており、これは220~351GBに相当します。このようなケースにおいて、最大の改善が見られます。結論として、我々の結果から以下のことがわかりました。
- GCがパフォーマンスのクリティカルパス上にない場合(concurrent GCではそのような状況にあってはいけないですが)、コレクターは「不必要な再配置を行う余裕がある」
- ヒープが逼迫している場合、よりポジティブな効果が現れ始める(Fig. 11参照)
- SPECjbb2015では、マシンが過剰に飽和し、GCと変異体がリソースを競合する状況において、すべてのヒープサイズで明確な改善が見られる
6 Related Work
mark–scavengeは、immixコレクターで使用されるopportunistic evacuation(機会主義的退避)と類似しています。これはコピーとマーキングを1回のパスで実行するものです。
opportunistic evacuationは、§2で議論した、退避時にworksetのサイズが不明であることに起因する、退避時に利用可能なto-spaceの予備が必要という問題に対処します。その解決策として、退避とインプレースマーキングの組み合わせをサポートし、to-spaceに空き領域がある限り、探索中に発見されたオブジェクトを移動させます。to-spaceに空き領域がなくなった時点で、有効オブジェクトはその場に残り、無効オブジェクトは解放され、オブジェクトの解放によって生じた連続した空き領域は、将来の割り当てのために再利用されます。したがって、オブジェクトをそのままにしておいても、GCによるメモリの再利用が妨げられることはありません。これは、生存オブジェクトをすべて移動させるのに十分な空き領域が存在する場合ほど、積極的なメモリの断片化解消ができないだけです。 opportunistic evacuationは、mark–scavengeと組み合わせ、scavengingに関する重要な懸念事項に対処します。opportunistic evacuationにおけるオブジェクトの移動とmark–scavengeの主な違いは、前者は空き領域が存在する間にオブジェクトが発見された場合にオブジェクトを移動させるのに対し、後者は空き領域がなくなった場合(インプレース圧縮またはjust-in-time evacuationによる)か、次のGCサイクルまでオブジェクトが生き残った場合にオブジェクトを移動させるという点です。シリアルとG1の無駄な作業に関する我々の結果が、immixにどの程度当てはまるかは明らかではありません。
リージョン内のメモリを回収して将来の割り当てに使用する能力は、opportunistic evacuationの鍵となりますが、mark-scavengeに追加するのは簡単ではありません。新しい割り当てと残存オブジェクトを単一のリージョンに混在させないので、前回のサイクルを使った有効性情報は控えめな過大推定になります。というのも、オブジェクトがその後で無効になっている可能性があるためです。これは、リージョンレベルでの混雑状況を判断するには十分です。リージョン内の空き領域への割り当てをサポートすると、リージョンの有効性情報が変わるため、このことは当てはまらなくなります。とはいえ、これはインプレース圧縮の代替案として、あるいはメモリ不足エラーを回避するための最終手段として、あるいはjust-in-time evacuationとして、今後の研究の興味深い方向性となるでしょう。
opportunistic evacuationを使用することで、immixコレクターはGCに必要なヘッドルームをmark–compact GCのヘッドルームに近づけることができました。concurrent GCのコンテキストでは、GC実行中、同時並行の割り当てをサポートするために追加のヘッドルームが必要です。 mark–scavengeは、この大きなヘッドルームを、無駄な再配置作業を回避することで、オブジェクトの移動を遅延させることができる、という利点に変えます。
§2.1で説明したように、 scavengingとは、オブジェクトグラフ走査時にオブジェクトが見つかれば、そのオブジェクトをコピーするという、GCアルゴリズムです。これにより、古くなった有効性情報によって無駄な再配置作業が発生するリスクが低減します。しかし、これはまた、有効オブジェクトがすべて再配置されるまで、すなわち有効性情報がすべて揃うまで、メモリの回収を先延ばしにすることにもなります。したがって、再配置作業の効率が低い場合に、使用頻度の低い領域のみを退避させることは不可能です。scavengingは、おそらくはスループットを最大化するためにGCサイクルの時間を最小化するように設計されているため、待ち時間を犠牲にして、youngコレクションに対する一般的な設計選択肢となっています。
参照カウント方式は、非トレース方式であり、各オブジェクト内のカウンタを通じて、すべてのオブジェクトへの入力ポインタを継続的に追跡することで、メモリの回収作業を時間をかけて分散し、迅速なメモリ回収を可能にします。これにより、GCのコストが平均化されます。多くのオブジェクトを時折トレースすることから、個々のオブジェクトの参照カウンタを継続的に増減させることまで、GCのコストは平均化されます。参照カウント方式では、アプリケーションのスレッドを完全に停止してメモリを回収する必要はありませんが、頻繁にアクセスされるオブジェクトでは、その参照カウンタを更新し続けなければならず、オーバーヘッドが発生します。このような余計なコストを回避するために、これらの問題に対処するために、更新の部分的削除、統合、および延期が提案されています。また、参照カウントにおけるデータ競合を回避するために、アトミック更新の必要性を排除するソリューションも提案されています。古くなった有効性情報に基づいて動作する状況では、このような最適化はかえって逆効果となる可能性があります。参照カウント法では、例えばプログラマーが弱参照(weak references)を指定したり、削除を試行したり、あるいは、最終的に循環を検出し収集するコンパニオン・トレーシング・コレクターに依存したりしない限り、循環データを処理できません。このようなコンパニオン・コレクターは、フラグメンテーションの処理にも役立ちます。
LXRコレクタ[31]は、Stop-the-World(STW)コピーGCと組み合わせて参照カウントを使い、高スループットで低レイテンシを可能にしています。トレースGCとは対照的に、LXRは参照カウントを減らすために無効オブジェクトをトレースすることを余儀なくされます。LXRは、STWトレースに費やす時間を短縮するために、非常に巧妙な最適化を採用しています。オブジェクトは参照カウント0で生成され、オブジェクトからの参照による参照カウントの増加は、オブジェクトが参照カウントを1に増加させるまでシステムには反映されません。この仕組みだと、多くのワークロードにおいて、ほとんどのオブジェクトは無効時に参照カウント0であるため、ほとんどの無効オブジェクトのトレースが回避されます。これは、MS-ZGCのようにオブジェクトが2度目に発見されるまで再配置を遅延させることと本質的には同じです。
ロードバリアを使用してアプリケーションのパフォーマンス(レイテンシではなくスループット)を向上させる例は[28]で紹介されています。この例では、キャッシュの局所性を向上させるために、ミューテーターによる再配置が使用されています。注目すべきは、この作業では、退避を遅延させることで、ミューテーターによってアクセスされる前にワーカー スレッドがオブジェクトを再配置しないようにしています。これは、再配置フェーズを次のマークの直前まで延期することで実現しています。さらに、次のマークで残りの再配置をすべて処理するようにしています。
7 Conclusions
私たちは、mark–scavengeという手法を提案しました。これは、よく知られたscavengingとmark–evacuateを組み合わせたもので、両方の長所を組み合わせたものだと考えています。オブジェクトを検出中に再配置し、迅速に1回で再配置できるだけでなく、同時に、迅速なメモリ回収や、より効率的な退避候補の選択に使用できる有効性情報も収集できます。オブジェクト再配置までの時間を遅らせることで、すでに無効のオブジェクトの再配置バイト量を大幅に削減できます。マシンのヘッドルームが低く、変更オブジェクトとGCワーカーがパフォーマンスを競い合う場合、コピーの削減はパフォーマンスの向上として現れます。
通常は「無駄」とされるメモリヘッドルームを資産として活用するため、ZGCのようなconcurrent GCにおいてmark-scavengeが追求する価値があることをこの論文が示していると私たちは考えています。さらに、この論文では、トレース・コレクターにおける無効オブジェクトのコピーの問題が明確に強調されています。
Data-Availability Statement
プロトタイプ実装は https://github.com/JonasNorlinder/mark-scavenge-oopsla24 にあります。アーカイブコピーは Norlinderらの研究 [21] にあります。
Acknowledgments
OOPSLA (Object-Oriented Programming, Systems, Languages & Applications) の匿名のレビューアーの方々からいただいたフィードバックにより、本論文を大幅に改善できました。
本研究は、Swedish Research Council(スウェーデン研究評議会)によるプロジェクト Accelerating Managed Languages (2020-05346) およびSwedish Foundation for Strategic Research(スウェーデン戦略研究財団)によるプロジェクト Deploying Memory Management Research in the Mainstream (SM19-0059) の支援、ならびにOracle Corporationからの寄付により実施されました。
ベンチマークは、National Academic Infrastructure for Supercomputing in Sweden(NAISS、スウェーデン国立学術インフラストラクチャ)が提供するマシン上で実施しました。その一部は、助成契約番号2022-06725を通じてSwedish Research Council(スウェーデン研究評議会)から資金提供を受けています。
References
[1] 2023. DaCapo 23.11-chopin. https://download.dacapobench.org/chopin/dacapo-23.11-chopin.zip.
[2] William Kemper Bernd Mathiske, Kelvin Nilsen and Ramki Ramakrishna. 2021. JEP 404: Generational Shenandoah(Experimental). https://openjdk.org/jeps/404
[3] Stephen M. Blackburn, Perry Cheng, and Kathryn S. McKinley. 2004. Myths and Realities: The Performance Impact ofGarbage Collection. SIGMETRICS Perform. Eval. Rev. 32, 1 (jun 2004), 25–36. https://doi.org/10.1145/1012888.1005693
[4] Stephen M. Blackburn, Robin Garner, Chris Hoffmann, Asjad M. Khang, Kathryn S. McKinley, Rotem Bentzur, AmerDiwan, Daniel Feinberg, Daniel Frampton, Samuel Z. Guyer, Martin Hirzel, Antony Hosking, Maria Jump, HanLee, J. Eliot B. Moss, Aashish Phansalkar, Darko Stefanović, Thomas VanDrunen, Daniel von Dincklage, and BenWiedermann. 2006. The DaCapo Benchmarks: Java Benchmarking Development and Analysis. In Proceedings ofthe 21st Annual ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages, and Applications(Portland, Oregon, USA) (OOPSLA ’06). Association for Computing Machinery, New York, NY, USA, 169–190. https://doi.org/10.1145/1167473.1167488
[5] Stephen M. Blackburn and Kathryn S. McKinley. 2003. Ulterior Reference Counting: Fast Garbage Collection withouta Long Wait. In Proceedings of the 18th Annual ACM SIGPLAN Conference on Object-Oriented Programing, Systems,Languages, and Applications (Anaheim, California, USA) (OOPSLA ’03). Association for Computing Machinery, NewYork, NY, USA, 344–358. https://doi.org/10.1145/949305.949336
[6] Stephen M. Blackburn and Kathryn S. McKinley. 2008. Immix: a mark-region garbage collector with space efficiency, fastcollection, and mutator performance. In Proceedings of the 29th ACM SIGPLAN Conference on Programming LanguageDesign and Implementation (Tucson, AZ, USA) (PLDI ’08). Association for Computing Machinery, New York, NY, USA,22–32. https://doi.org/10.1145/1375581.1375586
[7] C. J. Cheney. 1970. A non-recursive list compacting algorithm. Commun. ACM 13, 11 (nov 1970), 677–678. https://doi.org/10.1145/362790.362798
[8] David Detlefs, Christine Flood, Steve Heller, and Tony Printezis. 2004. Garbage-First Garbage Collection. In Proceedingsof the 4th International Symposium on Memory Management (Vancouver, BC, Canada) (ISMM ’04). Association forComputing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1029873.1029879
[9] L. Peter Deutsch and Daniel G. Bobrow. 1976. An efficient, incremental, automatic garbage collector. Commun. ACM19, 9 (sep 1976), 522–526. https://doi.org/10.1145/360336.360345
[10] Robert R. Fenichel and Jerome C. Yochelson. 1969. A LISP garbage-collector for virtual-memory computer systems.Commun. ACM 12, 11 (nov 1969), 611–612. https://doi.org/10.1145/363269.363280
[11] Christine H. Flood, Roman Kennke, Andrew Dinn, Andrew Haley, and Roland Westrelin. 2016. Shenandoah: An Open-Source Concurrent Compacting Garbage Collector for OpenJDK. In Proceedings of the 13th International Conferenceon Principles and Practices of Programming on the Java Platform: Virtual Machines, Languages, and Tools (Lugano,Switzerland) (PPPJ ’16). Association for Computing Machinery, New York, NY, USA, Article 13, 9 pages. https://doi.org/10.1145/2972206.2972210
[12] Andy Georges, Dries Buytaert, and Lieven Eeckhout. 2007. Statistically Rigorous Java Performance Evaluation. InProceedings of the 22nd Annual ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages andApplications (Montreal, Quebec, Canada) (OOPSLA ’07). Association for Computing Machinery, New York, NY, USA,57–76. https://doi.org/10.1145/1297027.1297033
[13] Richard Jones, Antony Hosking, and Eliot Moss. 2023. The Garbage Collection Handbook: The Art of Automatic MemoryManagement (second edition. ed.). CRC Press, Boca Raton, FL.
[14] Stefan Karlsson. 2021. JEP 439: Generational ZGC. https://openjdk.org/jeps/439
[15] Stefan Karlsson. 2022. Z Garbage Collector. Retrieved Feb 28, 2023 from https://wiki.openjdk.org/display/zgc/Main
[16] Jin-Soo Kim and Yarsun Hsu. 2000. Memory System Behavior of Java Programs: Methodology and Analysis. SIGMETRICSPerform. Eval. Rev. 28, 1 (jun 2000), 264–274. https://doi.org/10.1145/345063.339422
[17] Yossi Levanoni and Erez Petrank. 2001. An on-the-fly reference counting garbage collector for Java. In Proceedings ofthe 16th ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (Tampa Bay,FL, USA) (OOPSLA ’01). Association for Computing Machinery, New York, NY, USA, 367–380. https://doi.org/10.1145/504282.504309
[18] Yossi Levanoni and Erez Petrank. 2006. An On-the-Fly Reference-Counting Garbage Collector for Java. ACM Trans.Program. Lang. Syst. 28, 1, 1–69. https://doi.org/10.1145/1111596.1111597
[19] John McCarthy. 1960. Recursive functions of symbolic expressions and their computation by machine, part I. Commun.ACM 3, 4 (1960), 184–195.
[20] Jonas Norlinder, Erik Österlund, and Tobias Wrigstad. 2022. Compressed Forwarding Tables Reconsidered. In Proceedingsof the 19th International Conference on Managed Programming Languages and Runtimes (Brussels, Belgium) (MPLR ’22).Association for Computing Machinery, New York, NY, USA, 45–63. https://doi.org/10.1145/3546918.3546928
[21] Jonas Norlinder, Erik Österlund, David Black-Schaffer, and Tobias Wrigstad. 2024. [OOPSLA’24 Artefact] Mark–Scavenge:Waiting for Trash to Take Itself Out. https://doi.org/10.5281/zenodo.13361333
[22] Standard Performance Evaluation Corporation. 2015. SPECjbb® 2015. https://www.spec.org/jbb2015/
[23] Darko Stefanović, Matthew Hertz, Stephen M. Blackburn, Kathryn S. McKinley, and J. Eliot B. Moss. 2002. Older-First Garbage Collection in Practice: Evaluation in a Java Virtual Machine. SIGPLAN Not. 38, 2 supplement, 25–36. https://doi.org/10.1145/773039.773042
[24] Gil Tene, Balaji Iyengar, and Michael Wolf. 2011. C4: The continuously concurrent compacting collector. In Proceedingsof the international symposium on Memory management. 79–88.
[25] David Ungar. 1984. Generation Scavenging: A non-disruptive high performance storage reclamation algorithm.SIGPLAN Not. 19, 5 (apr 1984), 157–167. https://doi.org/10.1145/390011.808261
[26] B. L. Welch. 1947. The Generalization of ‘Student’s’ Problem when Several Different Population Variances are Involved.Biometrika 34, 1/2 (1947), 28–35. https://doi.org/10.2307/2332510
[27] Paul R. Wilson. 1992. Uniprocessor garbage collection techniques. In Memory Management, Yves Bekkers and JacquesCohen (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 1–42.
[28] Albert Mingkun Yang, Erik Österlund, and Tobias Wrigstad. 2020. Improving Program Locality in the GC UsingHotness. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation(London, UK) (PLDI 2020). Association for Computing Machinery, New York, NY, USA, 301–313. https://doi.org/10.1145/3385412.3385977
[29] Albert Mingkun Yang and Tobias Wrigstad. 2022. Deep Dive into ZGC: A Modern Garbage Collector in OpenJDK.ACM Transactions on Programming Languages and Systems (TOPLAS) (2022).
[30] Taiichi Yuasa. 1990. Real-time garbage collection on general-purpose machines. Journal of Systems and Software 11, 3(1990), 181–198. https://doi.org/10.1016/0164-1212(90)90084-Y
[31] Wenyu Zhao, Stephen M. Blackburn, and Kathryn S. McKinley. 2022. Low-Latency, High-Throughput GarbageCollection. In Proceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design andImplementation (San Diego, CA, USA) (PLDI 2022). Association for Computing Machinery, New York, NY, USA, 76–91. https://doi.org/10.1145/3519939.3523440
[32] Benjamin Zorn. 1990. Comparing Mark-and Sweep and Stop-and-Copy Garbage Collection. In Proceedings of the 1990ACM Conference on LISP and Functional Programming (Nice, France) (LFP ’90). Association for Computing Machinery,New York, NY, USA, 87–98. https://doi.org/10.1145/91556.91597
Received 2024-04-05; accepted 2024-08-18
